


8. Routage dynamique d'IP▲
8-1. Introduction et rappels▲
La notion de routage est inhérente au fonctionnement du datagramme IP.
Le routage des datagrammes IP n'est rien d'autre que l'opération qui consiste à trouver une route pour les conduire vers la destination, c'est-à -dire l'adresse du champ destination de l'entête.
Un premier examen du routage nous a conduit à distinguer le routage direct, sur un même LAN et associé à l'usage des services du protocole ARP puis le routage indirect, appelé ainsi parce qu'il fait appel aux services d'une ou plusieurs passerelles avant d'atteindre la destination. Dans les deux cas, la décision de routage porte sur la partie réseau de l'adresse IP du destinataire, ou encore le netid.
Le routage indirect se subdivise en deux catégories : le routage statique, qui implique l'usage d'une passerelle par défaut et enfin le routage dynamique, sujet qui concerne ce chapitre.
L'idée d'une route statique est séduisante par sa facilité de mise en œuvre pour l'organisation des « petits réseaux ». Elle se résume le plus souvent à ajouter une simple ligne dans la configuration de l'appareil à raccorder au réseau, et cette information vitale peut même être récupérée automatiquement à l'aide de protocoles comme BOOTP ou DHCP !
Sur un routeur CISCO(71), la ligne de configuration :
ip route 0.0.0.0 0.0.0.0 138.195.52.129Indique que tous les datagrammes non routables directement doivent être envoyés à l'adresse 138.195.52.129. Une seule route par défaut peut être définie pour une pile IP comme il a été expliqué lors de l'analyse de l'algorithme de routage.
Cette disposition très simple est bien commode, car elle évite de se poser des questions compliquées sur le choix de la route, en déléguant à d'autres ce travail délicat. En effet, il faudra bien à un certain moment du trajet suivi par les datagrammes, qu'un dispositif particulier, étymologiquement un routeur, prenne une décision face à des possibilités multiples.
Ce routeur plus intelligent sera probablement celui qui permet à vos datagrammes de rejoindre l'internet si vous appartenez à une entité qui a son autonomie (voir plus loin), ou le routeur du prestataire FAI pour un particulier, ou une plus petite entité, abonné à un service xDSL quelconque.
La présence de plusieurs routes possibles pour rejoindre une destination implique de facto l'usage d'un protocole de routage dynamique. Une route statique privilégie une seule route et ignore les autres. L'existence de plusieurs routes est une nécessité pour assurer la redondance du service, voire l'équilibrage du trafic sur plusieurs liens.
8-1-1. IGP, EGP, Système autonome▲
Au commencement, l'Arpanet était un seul réseau géré de manière homogène, du moins par un ensemble de personnes dépendantes de la même entité administrative, ce qui permettait d'en orienter le développement de la même manière partout. Le protocole de routage dynamique était un ancêtre du protocole RIP étudié dans ce chapitre. Ce protocole, comme on va le voir, implique que les routeurs s'échangent continuellement des informations sur les meilleures routes à employer. Sans entrave, chaque routeur finit par avoir une route pour atteindre tout le monde, partout !
L'extension de ce réseau à des entités très différentes entre elles, a conduit les architectes réseau de l'époque à créer la notion de système autonome (autonomous systems ou AS dans le texte), afin de permettre à chacun de développer son réseau interne sans risque d'en diffuser le contenu à l'extérieur (soucis de confidentialité et de sécurité).
Un système autonome se caractérise par un numéro, ou numéro d'AS, sur 16 bits dont l'attribution dépend de l'IANA et de ses délégations, par exemple autonomous-system 2192 que l'on pourrait retrouver dans la configuration d'un external gateway de la figure VII.01.
Cette nouvelle architecture entraîne des changements dans l'usage des protocoles de routage. Certains sont plus adaptés que d'autres à router des blocs d'adresses IP conformément à des politiques de routages (routing policy) internationales, ce sont les EGP comme external gateway protocol. Leur ancêtre se nomme d'ailleurs EGP, il est remplacé aujourd'hui par BGP (Border Gateway Protocol).
À l'intérieur du système autonome, les protocoles de routages sont des IGP comme Interior Gateway Protocol et ne sont plus du tout adaptés à la gestion de l'internet moderne. Par contre, ils répondent plus ou moins bien aux besoins des réseaux internes si compliqués et vastes soient-ils. Ces IGP échangent bien entendu des routes avec les EGP, le routage ne serait pas possible sans cela.
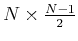
Ce chapitre de cours examine deux IGP très classiques, RIP et OSPF ! Si ces deux protocoles se rencontrent très fréquemment sur les réseaux, ils diffèrent beaucoup dans leurs propriétés comme nous allons le voir...
8-1-2. Vecteur de distances vs État de liens▲
RIP Routing Information Protocol et OSPF Open Shortest Path First sont construits sur des approches différentes.
Les algorithmes de routage à vecteur de distance (basés sur l'algorithme de Bellman-Ford) conduisent les routeurs à transmettre à leurs voisins réseau immédiats une copie de leur table de routage. Ces tables se modifient au fur et à mesure de leur propagation, car chaque route est associée à une métrique qui croît par défaut d'une unité au passage de chaque routeur (le routeur voisin accessible sur le même LAN est associé à une métrique de 1, etc.). Le choix de la meilleure route est établi par chaque routeur en considérant la valeur minimale de cette métrique pour toutes les routes qui aboutissent à la même destination. Seule la meilleure route est propagée, les autres sont oubliées.
Pour ces considérations on dit que le calcul de la route est distribué et par conséquent chaque routeur n'a pas la connaissance de la topologie globale du réseau : il n'en connaît qu'une version interprétée par ses voisins.
Les algorithmes à états de liens bâtissent les tables de routages différemment.
Chaque routeur est responsable de la reconnaissance de tous ses voisins, plus ou moins lointains, à qui il envoie une liste complète des noms et des coûts (en matière de bande passante, par défaut) contenus dans une base de données à sa charge et qui représente l'intégralité de tous les routeurs du nuage avec lesquels il doit travailler. Chaque routeur a donc une connaissance exhaustive de la topologie du « nuage » dans lequel il se situe et c'est à partir de cette représentation qu'il calcule ses routes à l'aide d'un algorithme connu de recherche du plus court chemin dans un graphe : celui de Dijkstra(72).
8-2. Routage avec RIP▲
RIP est l'acronyme de Routing Information Protocol. C'est le protocole historique de routage d'Arpanet(73), défini dans la RFC 1058 (historique) de 1988. Il est amusant de constater que l'écriture de cette RFC vient de l'analyse fonctionnelle du daemon routed présent sur les machines BSD de l'époque(74).
Le principe de fonctionnement de RIP est basé sur le calcul distribué du chemin le plus court dans un graphe, selon l'algorithme Bellman-Ford VII.5(75) décrit à la fin des années 1950.
Le terme chemin le plus court désigne implicitement l'usage d'une métrique pour comparer les longueurs. Ici, la métrique est basique, c'est le nombre de sauts (hops) entre deux routeurs. Pour tout routeur, les réseaux directement rattachés sont accessibles avec un nombre de sauts égal à 1 (par défaut). La métrique pour s'atteindre soi-même est toujours 0 par hypothèse.
Les routes qui sont propagées d'un routeur à un autre voient leur métrique augmenter de 1 (ou plus) à chaque franchissement d'un routeur. En pratique on ne dépasse guère une profondeur de quelques unités, sinon le protocole devient inefficace comme on le verra au paragraphe suivant. Plus précisément, une route assortie de la métrique 16 est considérée comme infinie, donc désigne une destination (devenue) inaccessible.
Cette limitation du protocole laisse quand même aux architectes d'infrastructures réseaux la possibilité de concevoir des réseaux séparés les uns des autres par un maximum de 15 routeurs... Au-delà de cette limite, il faut forcément envisager l'usage d'un autre protocole !
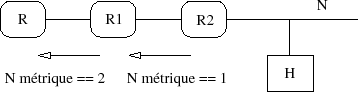
Sur la figure VII.02 le routeur R peut atteindre l'hôte H avec une route dont la métrique est 2 et qui passe par le routeur R1.
Il faut bien noter qu'avec RIP, chaque routeur n'est en relation qu'avec ses voisins directs, c'est-Ă -dire ceux avec lesquels il partage un LAN. Typiquement un routeur qui fait du RIP a au moins deux interfaces (elles peuvent ĂŞtre virtuelles), donc voit deux LAN. Ici R1 a un rĂ´le central et incontournable, car ni R ni R2 ne s'Ă©changent directement des routes.
Pour cette raison, les routes sont globalement issues d'un calcul distribué. Pour chaque routeur l'établissement de sa table de routage s'effectue à partir des informations fournies par les routeurs de son voisinage, c'est-à -dire ceux qu'il peut atteindre par un routage direct.
La connaissance des routes acquise par chaque routeur ne s'effectue qu'au travers du résultat des calculs de routes effectués par ses voisins, calculs qu'il confrontera à sa propre table de routage et à son propre calcul de route (le choix d'une route plus courte à l'aide de la métrique annoncée), puis diffusera à son tour. Par ce principe, dans la figure VII.02, R1 a connaissance du réseau N indirectement grâce aux annonces de routes diffusées par R2.
Le terme vecteur de distances est employé parce que la propagation des routes s'effectue sous la forme de vecteurs : « pour atteindre telle destination, il faut passer par ce routeur et la métrique associée vaut cette valeur ». Donc une direction et une métrique, d'où l'analogie avec un vecteur.
Le moyen de propagation des tables de routes est un broadcast IP (adresse 255.255.255.255 Limited broadcast pour RIPv1) ou des annonces multicast (adresse 224.0.0.9 si on utilise RIPv2(76)).
8-2-1. En fonctionnement▲
- 1/ Au démarrage, chaque routeur a connaissance des réseaux auxquels il est directement rattaché, ainsi que du coût associé à chacune de ses liaisons (1 par défaut).
Le coût de la liaison locale, c'est-à -dire celle du routeur vers lui-même, est « 0 » alors que celle pour atteindre n'importe quel autre point est « infini » (valeur 16 par défaut).
Le routeur envoie un paquet de questionnement (request packet) Ă ses voisins pour constituer sa table de routage initiale.
La RFC 2453 précise que celle-ci contient 5 informations pour chaque entrée :
-
- l'adresse IPv4 de la destination,
- la métrique pour atteindre cette destination,
- l'adresse IPv4 de première passerelle (next router) à utiliser,
- Un drapeau qui indique si la route a changé récemment (route change flag),
- deux chronomètres associés à la route, l'un pour signifier que la route n'est plus utilisable (timeout), l'autre pour compter le temps durant lequel une route non utilisable doit être maintenue dans la table avant d'être supprimée et l'espace mémoire utilisé recyclé (garbage-collection),
- en fonctionnement chaque routeur transmet son vecteur de distance Ă ses voisins directs (LAN) soit par un broadcast, soit par un multicast. Le port de destination est toujours 520Â ;
Cet événement a lieu périodiquement (30 secondes) où dès que quelque chose change dans la table de routage (Triggered updates page), ou encore à réception d'un paquet de demande de route, par exemple par un hôte d'un réseau directement raccordé ;
- 2/ Chaque routeur calcule son propre vecteur de distance, le coût minimum est le critère de sélection. Ce calcul intervient dès que :
- le routeur reçoit un vecteur de distance qui diffère avec ce qu'il a déjà en mémoire,
- le constat de la perte de contact (link ou absence de réception des annonces) avec un voisin.
- le routeur reçoit un vecteur de distance qui diffère avec ce qu'il a déjà en mémoire,
- le constat de la perte de contact (link ou absence de réception des annonces) avec un voisin.
Quand une route n'a pas été rafraîchie depuis 180 secondes (6 paquets de broadcast non reçus) sa métrique prend la valeur infinie (16) puis elle est détruite (deuxième chronomètre défini précédemment).
Le fonctionnement de RIP a un côté « magique » et pourtant l'algorithme converge vers un état stable, c'est démontré !
Examinons-en le fonctionnement élémentaire sur un réseau théorique de trois routeurs alignés lors d'un démarrage « à froid » :

À l'instant 0 chaque routeur découvre les réseaux qui lui sont directement rattachés et se connaît lui-même, c'est-à -dire qu'il connaît sa ou ses adresses IP. On peut le formaliser par un triplet (Destination, gateway, métrique), pour R1 ça donne (R1,local,0)(77) :
- R1 annonce (R1,local,0) sur N1Â ;
- R2 annonce (R2,local,0) sur N1 et N2Â ;
- R3 annonce (R3,local,0) sur N2.
En final chacun annonce ses routes de manière asynchrone, met à jour sa table de routage et annonce celle-ci, tout ça de manière un peu asynchrone. On examine les tables de routages une fois ces échanges stabilisés.
- R2 reçoit les annonces de route en provenance de R1 et R3. Il ajoute le coût de la liaison et obtient en final une table qui ressemble à  : (R2,local,0) (R1,R1,1) (R2,R2,1) ;
- De la même manière R1 enrichit sa table avec deux routes : (R2,R2,1) et (R3,R2,2) ;
- Pour R3 de manière symétrique : (R2,R2,1), (R1,R2,2).
Que se passe-t-il maintenant si R3 devient inaccessible (coupure réseau, hôte arrêté...) ?
Basiquement R2 devrait supprimer la route vers R3. Il n'en fait rien pour l'instant puisque R1 annonce une route (R3,R2,2). R2 décide donc qu'il existe une route (R3,R1,3) et annonce sa nouvelle table.
R1 ayant reçu une route modifiée de R2 modifie sa propre route qui devient (R3,R2,4) et ainsi de suite dans une boucle infernale qui tend à compter jusqu'à l'infini. For heureusement le calcul s'arrêtera à 16 par défaut, R1 et R2 concluront alors que R3 n'est pas (plus) accessible et finiront par retirer la route de leur table !
On peut aisément se rendre compte de la stupidité de cette démarche ainsi (et c'est surtout ce qu'on lui reproche) de la perte de temps engendrée. D'où les améliorations apportées :
8-2-1-1. Horizon partagĂ© ou Split horizon▲
Le concept est simple, il suffit de constater (toujours dans la figure VII.03) qu'il est stupide si R1 route via R2 des paquets pour R3, d'essayer pour R2 de router ces paquets vers R1.
Donc R1 ne doit pas annoncer à R2 des routes passant par R2. Les routes annoncées ne sont donc plus identiques sur chaque réseau, mais tiennent compte des destinations qui sont atteintes via chacune de ces liaisons pour éviter ce type d'annonce.
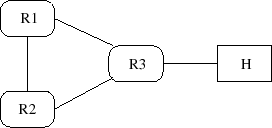
Il existe une variante plus efficace encore, qui consiste, pour R1, à annoncer à R2 la route (R3,R2,16), donc une route infinie. R2 ne pourra donc pas utiliser cette route pour atteindre R3 via R1. Il n'y a pas de boucle de comptage à l'infini et R2 conclura tout de suite à l'inaccessibilité de R3. Ces deux astuces réunies sont repérées dans la RFC sous le terme split horizon with poisoned reverse.
La figure VII.03 représente donc un cas théorique facile. En pratique, un des intérêts du routage dynamique étant d'avoir plusieurs routes possibles pour atteindre une destination, on aura plutôt la situation de la figure VII.04 ce qui amène au cas de figure suivant :
Supposons que l'hôte H devienne inaccessible, la technique ci-dessus empêchera R3 de tenter de router les datagrammes vers R1 et R2, mais, du fait du caractère asynchrone des mises à jour, R1 ayant reçu de R3 le fait que H est inaccessible peut conclure que R2 est le meilleur chemin avec un coût de 3 et cette fausse information peut se propager à R3 via R2 et le comptage à l'infini est reparti...
Pour y remédier, le protocole comporte un dispositif de mises à jour déclenchées :
8-2-1-2. Mises Ă jour dĂ©clenchĂ©es ou Triggered updates▲
L'éventualité d'une situation de comptage à l'infini évoqué dans le contexte de la figure VII.04 peut être endiguée par ce dispositif.
Seules des mises à jour très rapides peuvent conduire R1 et R2 à converger vers la conclusion que la distance vers H est devenue infinie.
La règle initiale est que quand un routeur change la métrique d'une route, il doit envoyer un message de mise à jour aussi vite que possible à tous ses voisins immédiats. Ce message ne contient que ce qui a changé et non l'intégralité de la table.
Mises à jour rapides ne signifient pas pour autant « tempêtes de paquets sur le réseau », d'une part parce que le principe de l'horizon partagé est conservé, et que d'autre part, une temporisation aléatoire (de 1 à 5 secondes) limite la fréquence d'émission de chaque mise à jour. Durant ce laps de temps la réception d'une mise à jour peut être également prise en compte et donc entrainer un changement des routes établies.
La différence entre ce dipositif et les annonces régulières tient à sa fréquence d'émission et au contenu restreint aux seules routes dont la métrique a changé.
La RFC 2453 conclut toutefois « However, counting to infinity is still possible ». Qui n'est vraiment pas très satisfaisant...
8-2-2. Le protocole RIPv1 vs RIPv2▲
RIP est encapsulé dans paquet UDP avec 520 comme port de destination :
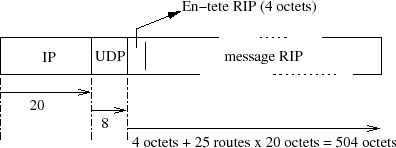
Étant donné le mode de propagation des annonces de routes, le choix du protocole UDP est tout à fait approprié. Cependant, la RFC 2453 spécifie que le nombre maximum de routes est limité à 25, comme il faut 20 octets (figure VII.06) pour décrire une route, la partie utile du datagramme fait au plus 4 + 25 x 20 = 504 octets et le datagramme complet 532 octets au maximum, le risque de fragmentation est nul sur des LAN et via les liaisons point à point modernes (PPP par exemple).
Par contre, s'il faut propager plus de 25 routes, il faut envisager l'émission d'autant de datagramme que nécessaire !
À l'intérieur du message RIP de la figure VII.03 les octets s'organisent de la manière suivante :
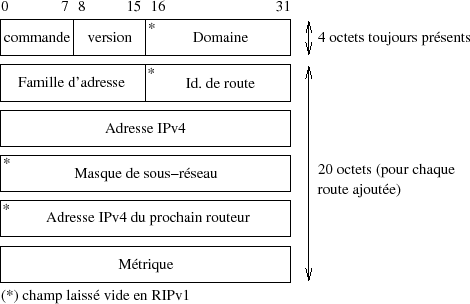
Le format d'un message RIP laisse plein d'espace vide (surtout quand il s'agit de RIPv1 -- les champs marqués d'une * sur la figure). L'alignement des champs sur des mots de 32 bits en est à l'origine.
- Commande 1 pour signifier une demande, request, et 2 pour une réponse, reply. D'autres commandes existent, mais elles sont obsolètes ou non documentées dans la RFC...
- Version 1 pour RIPv1 et 2 pour RIPv2Â ;
- Domaine (RIPv2) Pour pouvoir faire tourner simultanément sur une même machine plusieurs instances du daemon routed, ce champ contient un identifiant (PID...) qui permet de discriminer la provenance des routes ;
- Famille d'adresse (Address familly identifier - AFI) Famille d'adresse, comme pour un socket donc AF_INET pour IPv4. Ce champ peut également contenir la valeur hexadécimale 0xffff pour indiquer qu'il s'agit un bloc d'authentification. Dans ce cas l'identifiant de route contient la valeur 2 et les 16 octets qui suivent un mot de passe en clair, aligné à gauche et complété par des zéros ! Rien n'est défini dans la RFC 2453 pour être plus confidentiel...
- Identifiant de route (Route tag - RIPv2) C'est un « traceur » pour identifier une route qui provient d'un autre IGP voire d'un autre EGP et qui est propagée par RIP ;
- Adresse IPv4 Il s'agit de la destination à atteindre par le routeur qui émet cette annonce ;
- Masque de sous-réseau (RIPv2) Le masque de sous-réseau à appliquer au champ qui précède. C'est un des apports principaux de RIPv2 par rapport à RIPv1 ;
- Adresse IPv4 du prochain routeur (Next hop - RIPv2) En fonctionnement normal l'adresse 0.0.0.0 signifie que la route passe par celui qui l'annonce. Ici il s'agit d'une autre adresse IPv4, différente de celle de l'annonceur. Celui-ci n'utilise pas RIP (sinon il ferait l'annonce lui-même), mais sans doute un autre protocole de routage. Ce cas de figure arrive à la frontière entre deux réseaux, quand par exemple un routeur interne annonce une meilleure route via un routeur du même LAN ;
- Métrique Il s'agit de l'annonce de la métrique, de 0 (hôte local) à 16 (infini non accessible) en pratique.
En résumé, les apports de RIPv2 sont les suivants :
- Transmission d'un masque de sous-réseau avec chaque route. Ce point est majeur parce qu'il permet d'utiliser RIP avec des réseaux comportant des sous-réseaux ;
- Authentification (très insuffisante puisque le mot de passe circule en clair). Le constructeur Cisco a ajouté des extensions permettant l'usage de MD5, c'est mieux ;
- Indication d'un prochain routeur qui n'est pas celui qui annonce la route ;
- Indication de routes de provenances externes, ou route tag ;
- Usage de l'adresse multicast 244.0.0.9 pour propager des routes (plutĂ´t qu'un limited broadcast IP, plus perturbateur parce que lu par tous les hĂ´tes.
8-2-3. Algorithme Bellman-Ford▲
Pour le fonctionnement de l'algorithme, nous invitons le lecteur à consulter l'excellente simulation mise à disposition par l'Université Pierre Mendès France de Grenoble, à cette URL (cliquer sur le bouton « Appliquette ») :
- http://fr.wikipedia.org/wiki/Algorithme_de_Bellman-Ford
8-2-3-1. MĂ©trique▲
Dans les réseaux simples, le plus courant est d'utiliser le nombre de sauts, hop, c'est-à -dire le nombre de routeurs à franchir pour arriver à destination. Les réseaux plus complexes, on privilégiera une métrique basée sur le délai, par exemple.
8-2-4. Conclusion▲
L'apparition des protocoles à états de liens n'a pas empêché son développement, la RFC 2453 de 1998, décrit RIPv2 encore en usage dans bon nombre de (petits) réseaux.
8-2-4-1. Points forts▲
- Simplicité de mise en œuvre ;
- Simplicité du protocole permettant une compréhension aisée des échanges ;
- Robustesse des implémentations.
8-2-4-2. Points faibles▲
- Limitation a une profondeur de 15Â ;
- Problème de la vitesse de convergence (lente) de l'algorithme et du comptage éventuel jusqu'à la route infinie ;
- La métrique n'est pas adaptée à des réseaux dont les nœuds sont séparés par des liaisons utilisant des bandes passantes disparates ;
- L'authentification de l'émetteur des données est très pauvre en fonctionnalité et pas du tout « secure » ;
- La topologie des réseaux RIP reste à un seul niveau (pas de hiérarchie par exemple entre l'arête centrale d'un réseau (backbone) et des réseaux terminaux.
8-3. Routage avec OSPF▲
L'origine du protocole OSPF et de la technologie de routage par « état des liaisons » datent du tout début des années 1980, pour faire face aux insuffisances du protocole à vecteurs de distances, constatées sur les réseaux Arpanet et Cyclades. Son développement est dû aux efforts du groupe OSPF de l'IETF.
8-3-1. Grandes lignes de fonctionnement▲
Les explications qui suivent font l'hypothèse d'un réseau IP qui supporte la propagation de trames avec une adresse de destination de type multicast, autrement dit ne traite pas le cas des réseaux sans diffusion ce type ou encore NBMA (Non Broadcast MultiAccess networks).
Basiquement un protocole à états de liens a un fonctionnement simple :
- Chaque routeur est responsable de la reconnaissance de ses voisins (et donc de leur nom) directs, c'est-à -dire accessibles sur un des LAN directement raccordés ;
- Chaque routeur établit un paquet nommé link state packet (LSP) qui contient la liste des noms et des coûts (paragraphe 3.3.1) dans la métrique choisie pour atteindre chacun de ses voisins ;
- Le LSP est propagé à tous les routeurs et chacun conserve le plus récent LSP reçu des autres routeurs dans une base de données (link-state database). Chaque routeur du nuage travaille ainsi à partir des mêmes données, une sorte de carte globale des états ;
- Chaque routeur a la responsabilité par ses propres moyens (puissance CPU) du calcul du chemin à coût minimum (shortest path) à partir de lui-même et pour atteindre tous les nœuds du réseau ;
- Les changements de topologie du nuage (comme la perte de connectivité sur une interface) de routeurs sont rapidement détectés, annoncés au voisinage, et pris en compte pour recalculer les routes.
En résumé un tel protocole a deux grandes activités, la première est de propager ses états et d'écouter ceux de ces voisins au sein de l'AS, c'est ce qu'on appelle le flooding, en français procéder par inondation, la deuxième est de calculer des routes à partir de tous les états de liens reçus. Ce calcul est effectué à l'aide de l'algorithme de Dijkstra de recherche du plus court chemin dans un graphe.
Pour les réseaux complexes, OSPF permet le groupement de routeurs en zones distinctes, areas, qui établissent des nuages autonomes qui routent les datagrammes entre eux, mais ne laissent pas filtrer leur trafic interne de LSP. Se dégage ainsi une hiérarchie de routeurs, ceux qui sont au milieu de la zone, ceux qui en sont à la frontière et assurent les échanges avec les autres zones, enfin ceux qui assurent les échanges avec les EGP (comme BGP) pour le trafic externe à l'AS.
Tous les échanges sont authentifiés. Par ce biais, seulement les routeurs prévus dans la configuration participent au routage. La technique d'authentification peut différer d'une zone à une autre (cf paragraphe 3.7.2)
Enfin, les échanges de données sont structurés autour d'un protocole nommé HELLO. Ce protocole applicatif est véhiculé par deux adresses multicast qui lui sont attribuées : principalement 224.0.0.5 et 224.0.0.6 dans certains cas, voir le paragraphe 3.6). Le protocole est encapsulé directement dans les datagrammes IP, et le champ PROTO contient la valeur 89 (fichier /etc/protocols).
8-3-2. RIP vs OSPF▲
Le choix de l'un ou de l'autre est assujetti à l'examen de ce qui les différencie, que l'on résume dans les points suivants :
- RIP est limité à 15 sauts (hop), ce qui limite de facto la structure du nuage de routeurs ;
- Il faut utiliser RIPv2, car RIPv1 ne supporte pas la notion de masque de sous-réseau (Variable Length Subnet Mask ou VLSM) ;
- Plus le nuage est important et les liaisons moins performantes (comme sur un WAN) plus la diffusion périodique des tables de routages consomme des ressources (bande passante) ;
- RIP converge beaucoup plus lentement qu'OSPF. La conséquence d'un changement de la topologie peut mettre plusieurs minutes à être complètement intégrée, même avec l'usage des adresses multicast, des mises à jour déclenchées et du concept d'horizon partagé ;
- Le principe fondateur, nombre de sauts, ne tient pas compte des délais de propagation, le plus court chemin en matière de nombre de sauts ne désigne pas nécessairement le chemin qui offre le meilleur débit, sauf si tous les liens qui le composent sont de la même technologie (Ethernet 100BT par exemple) ;
- L'absence de la possibilité d'une structuration des routeurs RIP en zones ne permet pas une structuration intelligente des grands réseaux, surtout quand ils sont organisés avec des classes d'adresses que l'on puisse agréger entre elles en supernet) ;
- RIP n'a aucun mécanisme fiable d'authentification des annonces, ainsi n'importe quel hôte du réseau peut empoisonner l'ensemble avec des routes farfelues (ou malveillantes, ou les deux...) ;
- Le calcul des routes est distribué pour RIP, chaque routeur n'ayant qu'une vue partielle du nuage, alors que pour OSPF chaque routeur de la zone a une vue complète de l'état de tous les liens et établit lui-même le calcul des routes en se plaçant à la racine du graphe de destination.
En synthèse OSPF est plus performant sur les points suivants :
- Pas de limitation en nombre de sauts, cette donnée n'entre pas en ligne de compte puisque ce sont des états de liens qui sont propagés ;
- Les états de liens sont envoyés avec une adresse de destination multicast, et seules des mises à jour des états qui changent sont envoyées. La bande passante est préservée au maximum ;
- OSPF converge très vite, du fait de son mécanisme de propagation rapide (flooding) des états ;
- Le calcul du plus court chemin peut conduire à des routes de même valeur et OSPF est capable de gérer alors efficacement l'équilibre de la charge (load balancing) entre tous ces cheminements possibles ;
- L'organisation des grands réseaux en zones est complètement possible, ce qui d'une part réduit le trafic des états de liens et d'autre part permet des regroupements plus logiques basés sur les classes d'adresses IP ;
- Les informations échangées entre routeurs peuvent être authentifiées selon plusieurs méthodes, voire paragraphe 3.7.2 ;
- Les routes peuvent être étiquetées, ainsi les routes en provenance des EGP seront tracées et traitées spécifiquement.
8-3-3. Principe de propagation des Ă©tats▲
L'établissement des tables de routages dépend de la complétude d'une table appelée link-state database, base de données d'états de liens, présente à l'identique sur chaque routeur de la zone. Cette table est alimentée par les états de liens, Link State Packet (LSP), que s'envoient les routeurs entre eux. Or cette distribution dépend du routage...
Contrairement à ce que l'on pourrait en déduire, il n'y a pas de problème de préséance entre ces deux opérations, car la stratégie de distribution repose sur l'usage d'une adresse de multicast, valable uniquement dans un LAN donc qui ne dépend pas de l'état de la table de routage !
Chaque changement d'état sur un lien doit être signalé au plus vite à tous les voisins excepté celui qui a signalé le changement. C'est un procédé par inondation, ou flooding dans la littérature.
Intuitivement ce modèle de propagation semble rapide, mais génère potentiellement un nombre exponentiel de copies de chaque paquet...
Pour éviter une tempête prévisible de LSP, l'idée initiale des concepteurs consiste à ajouter à chaque LSP un numéro de séquence :
- chaque routeur conserve une trace du dernier numéro de séquence utilisé. Quand il génère un nouveau LSP il incrémente cette valeur ;
- quand un routeur reçoit un LSP depuis un voisin, il compare son numéro de séquence avec celui éventuellement déjà présent dans sa base de données :
- si le numéro est plus ancien, il oublie le paquet,
- si le numéro est plus récent il remplace éventuellement celui déjà présent en mémoire.
Ce dispositif tend à modérer la tempête de mises à jour, mais induit d'autres interrogations :
- Que faire quand on arrive à la valeur maximale du compteur (même avec des registres 64bits ça arrive un jour) ? Plus généralement comment déterminer la relation d'ordre entre deux LSP de valeur a et b ?
- Que se passe-t-il quand un routeur redémarre ? Il annonce des LSP avec un numéro de séquence plus petit que ceux déjà en circulation et qui donc seront ignorés, même si plus pertinents. Cette constatation est voisine de la situation de deux parties d'un même réseau, séparées à la suite d'une rupture de connectivité et qui se retrouvent mais après que l'un des compteurs soit repassé par 0 ?
Qui amènent les réponses suivantes :
- 1/ Le numéro de séquence est un compteur, avec une valeur minimale et maximale finie. Quand la valeur maximale est atteinte, il repasse par zéro, exactement comme un counter de SMI (chapitre concernant SNMP).
Ensuite, pour établir une relation d'ordre entre les LSP, la règle suivante est adoptée :
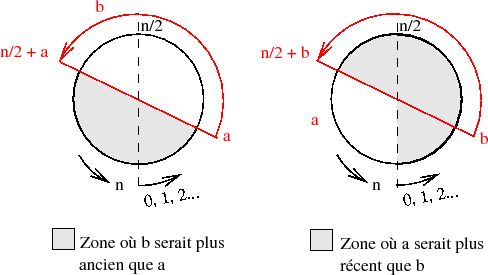
On peut déclarer que le LSP b est plus récent que a si les conditions :
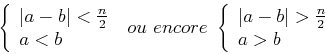
sont réunies. C'est ce que schématise graphiquement la figure VII.07 ci-dessus ;
- 2/ Pour répondre à la deuxième interrogation, on introduit une nouvelle donnée : l'âge du LSP. C'est une valeur numérique (codée sur 16 bits selon la RFC 2328) positionnée non nulle par le routeur qui émet le LSP :
- chaque routeur qui reçoit un LSP doit décrémenter l'âge d'au moins 1 unité et continuera ainsi dans le temps jusqu'à la valeur 0,
- à l'âge 0 le LSP ne doit plus être transmis, mais peut participer encore au calcul des routes,
- n'importe quel LSP (en matière de numéro de séquence) qui arrive avec un âge non nul peut remplacer un LSP d'âge nul,
- chaque routeur qui reçoit un LSP doit décrémenter l'âge d'au moins 1 unité et continuera ainsi dans le temps jusqu'à la valeur 0,
- à l'âge 0 le LSP ne doit plus être transmis, mais peut participer encore au calcul des routes,
- n'importe quel LSP (en matière de numéro de séquence) qui arrive avec un âge non nul peut remplacer un LSP d'âge nul.
En résumé :
- quand un routeur R génère un LSP, son numéro de séquence doit être plus grand de 1 (modulo n, cette dernière valeur étant la valeur maximale du compteur lui-même, par exemple 232 - 1) que la précédente séquence générée. L'âge doit être positionné à une valeur maximale ;
- quand un routeur autre que R reçoit le LSP, il l'accepte en remplacement de tout LSP avec un plus petit numéro de séquence (donc plus ancien) ;
- si l'âge du LSP stocké était 0, le nouvel LSP le remplace de manière inconditionnelle : on ne peut propager un LSP d'âge nul ;
- le véritable algorithme est plus complexe, voir la RFC 2328 page 143, The flooding procedure.
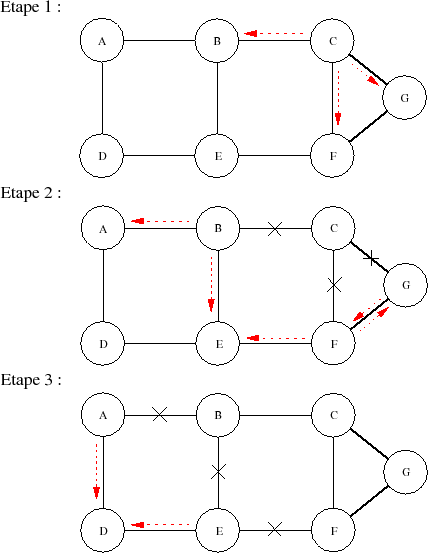
La figure VII.08 montre un exemple simple de propagation d'un changement d'état initié par le nœud C. En trois étapes tous les routeurs sont mis au courant. À l'étape 2 on peut remarquer que les routeurs B,F et G s'interdisent de renvoyer le LSP à C, son émetteur. On remarque également que F et G s'envoient le même paquet, mais celui issu de F a un âge plus ancien, il sera donc oublié immédiatement, comme celui issu de G, pour la même raison.
Le nœud E reçoit le même LSP depuis B et F, le premier arrivé sera pris en compte, le deuxième oublié. Même remarque pour D à la fin de la troisième étape.
La durée totale de ces trois étapes est pratiquement celle nécessaire pour propager les datagrammes (donc fortement dépendante de la bande passante), de quelques millisecondes à quelques centaines de millisecondes, donc !
8-3-3-1. Valeur des Ă©tats de liens▲
Le coût des liens, nommé également la métrique, agit directement sur le choix d'une route plutôt qu'une autre comme on le voit dans le paragraphe qui suit.
Le constructeur Cisco préconise(78) une formule qui est reprise partout :
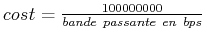
bps signifie bits per second. Ce qui signifie qu'une liaison Ethernet à 10Mbits (dix millions de bits par seconde, un million d'octets par secondes) a un coût de 108 / 107 = 10.
Le petit tableau ci-dessous indique quelques valeurs pour des débits connus :
| Média | Coût |
| Liaison série 56kbps | 1785 |
| T1 (série 1544 kbps) | 64 |
| E1 (série 2048 kbps) | 48 |
| Token ring 4Mbps | 25 |
| Ethernet 10Mbps | 10 |
| Token ring 16Mbps | 6 |
| Ethernet 100Mbps | 1 |
| ... | ... |
Bien entendu on peut toujours imposer manuellement sa propre valeur de coût d'une liaison, pour influencer le routage !
8-3-4. Calcul du plus court chemin▲
Pour le fonctionnement de l'algorithme de Dijkstra nous invitons le lecteur à consulter l'excellente simulation mise à disposition par l'Université Pierre Mendès France de Grenoble, à cette URL (cliquer sur le bouton « Appliquette ») :
- http://fr.wikipedia.org/wiki/Algorithme_de_Dijkstra.
8-3-5. HiĂ©rarchie de routeurs▲
Les réseaux à administrer peuvent être vastes et complexes, dans ces conditions il est souvent pertinent de les regrouper en sous-ensembles. La conception d'OSPF permet de le faire, il s'agit d'un concept nommé zone ou (area) et qui se traduit par une hiérarchisation du routage.
Outre la structuration plus claire du réseau global en sous-réseaux, l'avantage de cette approche est également de diminuer le nombre de routes sur lequel porte le calcul de plus court chemin, et aussi de diminuer le trafic des mises à jour, non négligeable sur un réseau vaste et complexe.
La RFC précise qu'une zone doit faire le lien avec toutes les autres, il s'agit forcément de la zone 0, qui joue donc le rôle de l'arête centrale (OSPF Backbone).
De cette structuration découle le fait que tous les routeurs n'ont pas le même rôle, certain sont au milieu d'une zone et d'autres à la frontière entre deux zones, voire à la frontière entre le nuage OSPF et d'autres mécanismes de routage, vers d'autres AS :
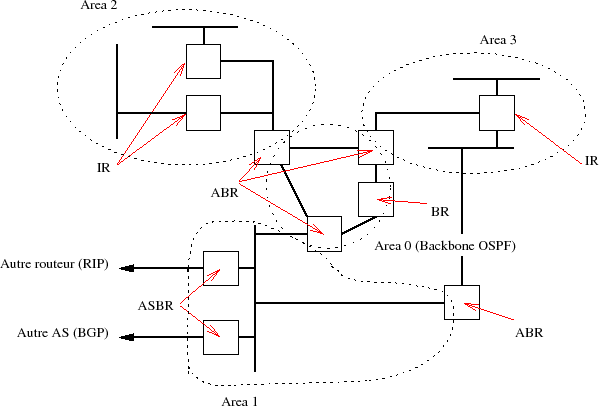
La RFC précise quatre types de routeurs dans ce cas de figure :
- Internal routers (IR) : c'est le cas le plus simple d'un routeur au milieu d'un nuage à l'intérieur d'une zone. Il n'a qu'une seule base d'états de liens qu'il met à jour avec les autres routeurs de son voisinage ;
- Area border routers (ABR) : ces routeurs se trouvent attachés à au moins deux zones. Ils possèdent autant de bases de données d'états de liens qu'ils ont d'interfaces connectées à des zones différentes. Ces bases diffèrent, car elles concernent des nuages différents. Elles doivent être propagées vers la zone 0 sous forme d'une route résumée (summarized) qui utilise au mieux les possibilités du CIDR. Bien entendu cela suppose que les réseaux puissent être agrégés entre eux ;
- Backbone routers (BR) : il s'agit de routeurs qui sont raccordés au moins à la zone 0. LA RFC n'est pas claire sur leur signification exacte...
- Autonomous system boundary routeurs (ASBR) : c'est le (les) routeur(s) qui marque(nt) la frontière d'influence de l'IGP. Il peut être en relation avec n'importe quel autre protocole de routage, par exemple RIP et BGP sur la figure VII.09 avec lesquelles il établit des passerelles et échange des routes. Les usagers de l'IGP ont besoin d'échanges avec l'extérieur (autres réseaux, autres AS).
8-3-6. Fonctionnement Ă l'intĂ©rieur d'une zone▲
Le fonctionnement du mécanisme d'inondation à l'intérieur d'une zone, tel que nous l'avons succinctement décrit au paragraphe 3.3, induit que lors de la diffusion d'un LSP chaque routeur propage le changement d'état reçu à son voisinage réseau. Ce comportement induit un trafic en N2, si N est le nombre de routeurs sur le LAN en question.
OSPF essaie de réduire ce nombre à seulement N en faisant jouer un rôle particulier à l'un des routeurs, le routeur désigné, ou Designated Router (DR). Celui-ci reçoit les mises à jour, car il écoute sur une autre adresse multicast, 224.0.0.6 (tous les routeurs OSPF désignés) et si besoin est propagé à nouveau cette information vers les autres routeurs du LAN, avec ce coup-ci l'adresse 224.0.0.5 (tous les routeurs OSPF).
Se pose immédiatement la question de la panne éventuelle du routeur DR, celle-ci bloquerait la mise à jour des bases d'états de liens. À cet effet un routeur désigné de sauvegarde est également élu, c'est le Backup Designated Router, mis à jour en même temps que le DR, mais qui reste muet sur le réseau tant que le protocole HELLO n'a pas détecté un dysfonctionnement du DR.
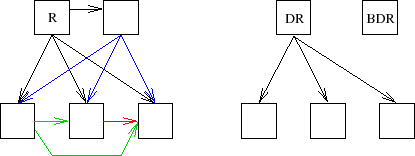
Sur la figure VII.10, schéma de gauche, le routeur R propage un nouvel LSP à tous ses voisins, puis chacun propage ce qu'il a reçu vers les voisins pour lesquels il n'a rien reçu. Le nombre de paquets est alors en théorie celui du nombre de paires possibles(79), soit encore :
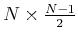
pour cet exemple.
Pour le schéma de droite, le routeur DR a reçu un LSP et le diffuse aux trois routeurs concernés. Notons que le BDR ne fait rien, il a également reçu la mise à jour, mais s'abstient de toute action tant que le DR est opérationnel.
Avant de pouvoir établir une hiérarchie entre eux et d'échanger efficacement des états de liens, les routeurs doivent déterminer qui sont leurs voisins, autrement dit la topologie du réseau qui les entoure.
8-3-6-1. Voisinage et adjacence▲
La RFC 2328 définit une progression selon 8 états (7 pour les réseaux avec propagation par multicast) pour chaque routeur OSPF, avant de pouvoir échanger efficacement avec ses voisins. Il est utile d'en avoir connaissance pour diagnostiquer une situation.
L'établissement (ou non) de ces états repose sur la structuration du protocole HELLO, qui se décline en cinq types de paquets différents, nous les examinons au paragraphe 3.7 :
- Down : c'est l'état initial, préalable à tout établissement d'une conversation avec le voisinage. Il indique qu'aucune activité de voisinage n'a été détectée depuis un moment ;
- Init : ces routeurs envoient des paquets de type Hello à fréquence régulière (environ 10 secondes). La réception d'un tel paquet suffit pour passer à cet état. Dans la liste des voisins transmise dans le paquet le routeur n'apparaît pas, la communication reste unidirectionnelle ;
- Two-way : un routeur entre dans cet état s'il se voit dans le paquet Hello propagé par un voisin. La communication est alors bidirectionnelle. Cet état est la relation de voisinage la plus basique. Pour pouvoir échanger des états de liens et construire des routes, chaque routeur doit former une contiguïté (adjacency) avec chacun de ses voisins. C'est une relation avancée entre routeurs OSPF. Elle s'établit en commençant par l'état suivant ;
- ExStart : c'est le premier pas pour constituer une contiguïté de routeurs entre deux voisins. Le but de cette étape est de décider qui sera le maître et l'esclave dans la relation. Des paquets de type DataBase Description paquet sont échangées, et le routeur ayant la plus forte valeur de RID (Router ID) gagne. Cette dernière valeur est fonction de l'adresse IP la plus élevée pour toutes les interfaces du routeur, et d'un coefficient configuré manuellement (non démocratique) ;
- Exchange : les routeurs s'échangent l'intégralité de leur base d'états de liens à l'aide de paquets DBD ;
- Loading : à ce stade les routeurs terminent de compléter leur table de liens. Les états qui ont besoin d'être rafraîchis font l'objet de requêtes à l'aide de paquets de type Link-state request (LSR) auxquels sont répondus des paquets de type Link-state update (LSU) (Voir paragraphe 3.7) qui contiennent les LSP, appelés LSA en pratique, cur du fonctionnement du protocole. Les LSU sont acquittés par des Link-state acknowledgment (LSAck) ;
- Full : une fois atteint cet état, l'adjacence d'un routeur avec un voisin est complète. Chaque routeur conserve une liste de ses voisins dans une base de données adjacency database.
8-3-7. Protocole HELLO▲
Le protocole HELLO est en charge de l'établissement et du maintien des relations de voisinage entre routeurs. Il s'assure également que les communications entre chaque voisin sont bidirectionnelles. Comme nous l'avons précisé en introduction, ce paquet est encapsulé dans un datagramme IP, donc en lieu et place d'un protocole de transport (qu'il ne remplace pas).
Des paquets de type HELLO sont envoyés à fréquence périodique sur toutes les interfaces des routeurs. Les communications sont repérées comme étant bidirectionnelles si un routeur se reconnaît dans la liste (des voisins connus) émise dans le paquet HELLO d'un voisin. Le protocole sert également à l'élection du Routeur Désigné (DR).
Sur les réseaux permettant le multicast, chaque routeur s'annonce lui-même en envoyant périodiquement des paquets HELLO. Ce dispositif permet aux routeurs voisins de se connaître dynamiquement, de vérifier continuellement l'accessibilité des voisins déjà connus.
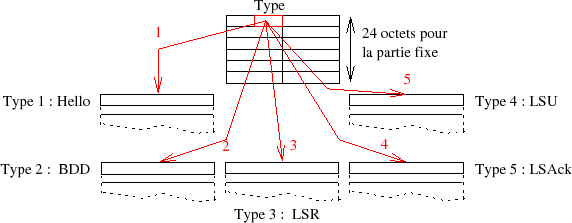
8-3-7-1. Cinq types de paquets▲
Le protocole HELLO se compose principalement d'un entête de 6 mots de 4 octets (24 octets) et d'un complément qui dépend du type de paquet. Ce type est défini dès le premier mot de l'entête.
- Hello (type 1)Â : ce paquet Ă©tablit et maintient les relations de voisinage (adjacency information)Â ;
- DataBase : description paquet (type 2) (DBD) Sert à décrire le contenu des bases de données d'états de liens des routeurs OSPF lors de l'établissement d'une contiguïté de routeurs. De multiples paquets de ce type peuvent être envoyés pour décrire l'intégralité de la base de données ;
- Link-state request (type 3) (LSR) : une fois échangée la description de la base d'états, un routeur peut s'apercevoir qu'une partie des liens sont périmés (date de fraîcheur). Ce type 3 est alors utilisé pour requérir du voisin une mise à jour. De multiples paquets peuvent être envoyés ;
- Link-state update (type 4) (LSU) : ces paquets sont utilisés par le procédé d'inondation présenté au paragraphe 3.3. Chacun d'eux transporte une collection de LSP (on les nomme également LSA) à destination du voisinage immédiat. Pour rendre la procédure d'inondation efficace, ces paquets doivent être explicitement acquittés par des paquets de type 5 ;
- Link-state acknowledgment (type 5) (LSAck) : chaque LSA envoyé est acquitté par l'émission d'un paquet de type 5. Plusieurs acquittements peuvent être combinés dans un seul paquet. L'adresse IP de destination peut prendre une valeur multicast ou unicast.
8-3-7-2. EntĂŞte standard des paquets OSPF▲
Tous les paquets OSPF démarrent par un en-tête standard de 24 octets :
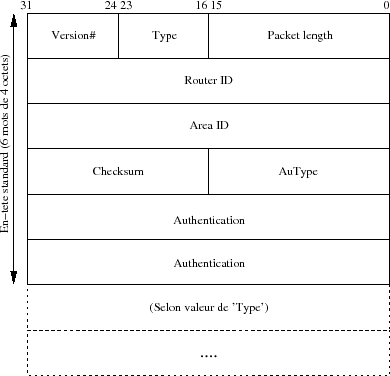
- Version : la valeur 2 est requise, c'est la version du protocole ;
- Type : une valeur comprise entre 1 et 5 qui détermine la partie variable de l'entête ;
- Packet length : longueur du paquet en octets, y compris l'en-tête ;
- Routeur IDÂ : c'est l'identifiant du routeur (RID)Â ;
- Area ID : c'est le numéro de la zone. La représentation décimale pointée est utilisée, par exemple pour la zone backbone ce champ vaut 0.0.0.0 ;
- Checksum : il porte sur la totalité du paquet moins cette zone et les 8 octets du champ Authentication ;
- AuType : tous les échanges sont authentifiés. Ce champ en décrit la méthode. Trois valeurs sont prévues par la RFC :
| AuType | Description |
| 0 | Pas d'authentification |
| 1 | Mot de passe en clair sur le réseau |
| 2 | Crypto à partir d'un secret partagé |
- Authentication 64 bits qui sont utilisés selon la valeur du champ précédent.
8-3-7-3. EntĂŞte des paquets HELLO▲
Un paquet de type 1 (Hello) est envoyé périodiquement sur toutes les interfaces des routeurs qui participent au nuage OSPF. L'objectif est de maintenir les relations de voisinage et d'adjacences comme vu précédemment. C'est une sorte de Keep-alive pour les besoins du protocole.
Les octets de la figure VII.13 sont à placer en continuité de ceux de la figure VII.12, pour former un en-tête de 24 + 24 = 48 octets minimums. La taille s'accroît ensuite de quatre octets par RID supplémentaire de voisin.
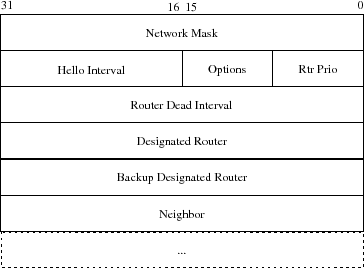
- Network Mask : le masque de sous réseau associé à l'interface ;
- Options : les options du routeur. Cinq bits sont utilisés seulement pour décrire des possibilités annexes au fonctionnement global ;
- Hello : interval Le nombre de secondes entre deux paquets de ce type ;
- Rtr Prio : la priorité de ce routeur. C'est une valeur positionnée manuellement dans la configuration et qui a un impact direct sur le résultat de l'élection des DR et BDR. Une valeur 0 n'a aucun impact, alors que 255 assure quasiment le routeur d'être DR ;
- Router Dead Interval : le nombre de secondes avant de déclarer inatteignable un routeur devenu silencieux ;
- Designated Router : c'est l'adresse IP du DR pour ce LAN. Ce champ est à 0.0.0.0 s'il n'y en a pas ;
- Backup Designated Router : idem pour le BDR ;
- Neighbor : il s'agit de la liste des RID (Router ID) des voisins connus et de qui on a reçu récemment (c'est-à -dire avec un délai inférieur à la valeur du champ Router Dead Interval) un paquet de type 1 ;
- La description des 4 autres types de paquets se trouve Ă l'annexe A.3 de la RFC.
8-4. Bibliographie▲
Pour en savoir plus :
- RFC 1058 « Routing Information Protocol. » C.L. Hedrick. June 1988. (Format: TXT=93285 bytes) (Updated by RFC1388, RFC1723) (Status: HISTORIC)
- RFC 1247 « OSPF Version 2. » J. Moy. July 1991. (Format: TXT=433332, PS=989724, PDF=490300 bytes) (Obsoletes RFC1131) (Obsoleted by RFC1583) (Updated by RFC1349) (Also RFC1246, RFC1245) (Status: DRAFT STANDARD)
- RFC 2328 « OSPF Version 2. » J. Moy. April 1998. (Format: TXT=447367 bytes) (Obsoletes RFC2178) (Also STD0054) (Status: STANDARD)
- RFC 2453 « RIP Version 2. » G. Malkin. November 1998. (Format: TXT=98462 bytes) (Obsoletes RFC1723) (Also STD0056) (Status: STANDARD)
Sites web :
- CISCO OSPF Design Guide http://www.cisco.com/warp/customer/104/1.html
- Algorithme de Bellman-Ford http://fr.wikipedia.org/wiki/Algorithme_de_Bellman-Ford
- Algorithme de Dijkstra http://fr.wikipedia.org/wiki/Algorithme_de_Dijkstra
Ouvrages de référence :
- W. Richard Stevens - TCP/IP Illustrated, Volume 1 - The protocols - Addison-Wesley
- Christian Huitema - Le routage dans l'Internet - EYROLLES
- Radia Perlman -- « Interconnections Second Edition » - Briges, Routers, Switches, and Internetworking Protocoles -- Addison-Wesley