


15. √âl√©ments de serveurs▲
Dans ce chapitre nous abordons quelques grands principes de fonctionnement des logiciels serveurs. D'abord nous tentons de résumer leurs comportements selon une typologie en quatre modèles génériques, puis nous examinons quelques points techniques remarquables de leur architecture logicielle comme la gestion des tâches multiples, des descripteurs multiples, le fonctionnement en arrière-plan (les fameux « daemon »), la gestion des logs...
Enfin nous concluons ce chapitre avec une présentation très synthétique du « serveur de serveurs » sous Unix, c'est-à-dire la commande inetd, suivie d'une lecture commentée d'un petit code en langage C qui s'inspire de son fonctionnement, pour mieux comprendre sa stratégie !
15-1. Type de serveurs▲
L'algorithme intuitif d'un serveur, déduit des schémas d'utilisation des sockets, pourrait être celui-ci :
- Créer une socket, lui affecter une adresse locale avec un numéro de port connu des clients potentiels ;
- Entrer dans une boucle infinie qui accepte les requêtes des clients, les lit, formule une réponse et la renvoie au client.
Cette démarche, que nous pourrions qualifier de naïve, ne peut convenir qu'à des applications très simples. Considérons l'exemple d'un serveur de fichiers fonctionnant sur ce mode. Un client réseau qui s'y connecte et télécharge pour 10 Go de données accapare le serveur pendant un temps significativement long, même au regard des bandes passantes modernes. Un deuxième client réseau qui attendrait la disponibilité du même serveur pour transférer 1 Ko aurait des raisons de s'impatienter !
15-1-1. Serveurs it√©ratif et concourant▲
Un serveur itératif (« iterative server ») désigne une implémentation qui traite une seule requête à la fois.
Un serveur concourant (« concurrent server ») désigne une implémentation capable de gérer plusieurs tâches en apparence simultanées. Attention, cette fonctionnalité n'implique pas nécessairement que ces tâches concourantes doivent toutes s'exécuter en parallèle... Dans cette première approche purement algorithmique, nous n'abordons pas la mise en œuvre technique, le paragraphe 2 s'y consacrera !
D'un point de vue conceptuel, les serveurs itératifs sont plus faciles à concevoir et à programmer que les serveurs concourants, mais le résultat n'est pas toujours satisfaisant pour les clients. Au contraire, les serveurs concourants, s'ils sont d'une conception plus savante, sont d'un usage plus agréable pour les utilisateurs parce que naturellement plus disponibles.
15-1-2. Le choix d'un protocole▲
La pile ARPA nous donne le choix entre TCP et UDP. L'alternative n'est pas triviale. Le protocole d'application peut être complètement bouleversé par le choix de l'un ou de l'autre. Avant toute chose il faut se souvenir des caractéristiques les plus marquantes de l'un et de l'autre.
15-1-2-1. Mode connect√©▲
Le mode connecté avec TCP est le plus facile à programmer, de plus il assure que les données sont transmises, sans perte.
Par contre, il établit un circuit virtuel bidirectionnel dédié à chaque client ce qui monopolise une socket, donc un descripteur, et interdit par construction toute possibilité de « broadcast ».
L'établissement d'une connexion et sa terminaison entraîne l'échange de sept paquets. S'il n'y a que quelques octets à échanger entre le client et le serveur, cet échange est un gaspillage des ressources du réseau.
Il y a plus préoccupant. Si la connexion est au repos, c'est-à-dire qu'il n'y a plus d'échange entre le client et le serveur, rien n'indique à celui-ci que le client est toujours là ! TCP est silencieux si les deux parties n'ont rien à s'échanger(182).
Si l'application cliente a été interrompue accidentellement(183), rien n'indique au serveur que cette connexion est terminée et il maintient la socket et les buffers associés. Que cette opération se répète un grand nombre de fois et le serveur ne répondra plus, faute de descripteur disponible, voire de mémoire libre au niveau de la couche de transport (allocation au niveau du noyau, en fonction de la mémoire totale et au démarrage de la machine) !
15-1-2-2. Mode datagramme▲
Le mode datagramme ou « non connecté » avec UDP hérite de tous les désagréments de IP, à savoir perte, duplication et désordre introduit dans l'ordre des datagrammes.
Pourtant malgré ces inconvénients UDP reste un protocole qui offre des avantages par rapport à TCP. Avec un seul descripteur de socket un serveur peut traiter un nombre quelconque de clients sans perte de ressources due à de mauvaises déconnexions. Le « broadcast » et le « multicast » sont possibles.
Par contre les problèmes de fiabilité du transport doivent être gérés au niveau de l'application. Généralement c'est la partie cliente qui est en charge de la réémission de la requête si aucune réponse du serveur ne lui parvient.
La valeur du temps au-delà duquel l'application considère qu'il doit y avoir réémission est évidemment délicate à établir. Elle ne doit pas être figée aux caractéristiques d'un réseau local particulier et doit être capable de s'adapter aux conditions changeantes d'un internet.
15-1-3. Quatre mod√®les de serveurs▲
Deux comportements de serveurs et deux protocoles de transport combinés induisent quatre modèles de serveurs :

La terminologie « tâche esclave » employée dans les algorithmes qui suivent se veut neutre quant au choix technologique retenu pour les implémenter. Ce qui importe c'est leur nature concourante avec la « tâche maître » qui les pilote.
Algorithme itératif - Mode data-gramme
- Créer une socket, lui attribuer un port connu des clients.
- Répéter :
- Lire une requête d'un client,
- Formuler la réponse,
- Envoyer la réponse, conformément au protocole d'application.
Critique :
- Cette forme de serveur est la plus simple, elle n'est pas pour autant inutile. Elle est adaptée quand il y a un tout petit volume d'information à échanger et en tout cas sans temps de calcul pour l'élaboration de la réponse. Le serveur de date « daytime » ou le serveur de temps « time » en sont d'excellents exemples.
Algorithme Itératif - Mode connecté :
- Créer une socket, lui attribuer un port connu des clients.
- Mettre la socket à l'écoute du réseau, en mode passif.
- Accepter la connexion entrante, obtenir une socket pour la traiter.
- Entamer le dialogue avec le client, conformément au protocole de l'application.
- Quand le dialogue est terminé, fermer la connexion et aller en 3).
Critique :
- Ce type de serveur est peu utilisé. Son usage pourrait être dédié à des relations clients/serveurs mettant en jeu de petits volumes d'informations avec la nécessité d'en assurer à coup sûr le transport. Le temps d'élaboration de la réponse doit rester court.
- Le temps d'établissement de la connexion n'est pas négligeable par rapport au temps de réponse du serveur, ce qui le rend peu attractif.
Algorithme concourant - Mode datagramme :
Maître :
- Créer une socket, lui attribuer un port connu des clients.
- Répéter :
- Lire une requête d'un client,
- Créer une tâche esclave pour élaborer la réponse,
Esclave :
- Recevoir la demande du client ;
- Élaborer la réponse ;
- Envoyer la réponse au client, conformément au protocole de l'application ;
- Terminer la t√¢che.
Critique :
- Si le temps d'élaboration de la réponse est rendu indifférent pour cause de création de processus esclave, par contre le coût de création de ce processus fils est prohibitif par rapport à son usage : formuler une seule réponse et l'envoyer. Cet inconvénient l'emporte généralement sur l'avantage apporté par le « parallélisme ».
- Néanmoins, dans le cas d'un temps d'élaboration de la réponse long par rapport au temps de création du processus esclave, cette solution se justifie.
Algorithme concourant - Mode connecté :
Maître :
- Créer une socket, lui attribuer un port connu des clients ;
- Mettre la socket à l'écoute du réseau, en mode passif ;
- Répéter :
- Accepter la connexion entrante, obtenir une socket pour la traiter,
- Créer une tâche esclave pour traiter la réponse,
Esclave :
- Recevoir la demande du client ;
- Amorcer le dialogue avec le client, conformément au protocole de l'application ;
- Terminer la connexion et la t√¢che.
Critique :
- C'est le type le plus général de serveur parce qu'il offre les meilleures caractéristiques de transport et de souplesse d'utilisation pour le client. Il est surdimensionné pour les « petits » services et sa programmation soignée n'est pas toujours à la portée du programmeur débutant.
15-2. Technologie √©l√©mentaire▲
De la partie algorithmique découlent des questions techniques sur le « comment le faire ». Ce paragraphe donne quelques grandes indications très élémentaires que le lecteur soucieux d'acquérir une vraie compétence devra compléter par les lectures indiquées au dernier paragraphe ; la bibliographie du chapitre. Notamment il est nécessaire de consulter les ouvrages de W. R. Stevens pour la partie système et David R. Butenhof pour la programmation des threads.
La suite du texte va se consacrer à éclairer les points suivants :
- Gestion des « tâches esclaves » (paragraphes 2.1, 2.2, 2.3, 2.4)
- Gestion de descripteurs multiples (paragraphes 2.5, 2.6)
- Fonctionnement des processus en arrière-plan ou « daemon » (paragraphe 3)
15-2-1. Gestion des ¬´¬†t√¢ches esclaves¬†¬ª▲
La gestion des « tâches esclaves » signalées dans le paragraphe 1 induit que le programme « serveur » est capable de gérer plusieurs actions concourantes, c'est-à-dire qui ont un comportement qui donne l'illusion à l'utilisateur que sa requête est traitée dans un délai raisonnable, sans devoir patienter jusqu'à l'achèvement de la requête précédente.
C'est typiquement le comportement d'un système d'exploitation qui ordonnance des processus entre eux pour donner à chacun d'eux un peu de la puissance de calcul disponible (« time-sharing »).
La démarche qui parait la plus naturelle pour implémenter ces « tâches esclaves » est donc de tirer parti des propriétés mêmes de la gestion des processus du système d'exploitation.
Sur un système Unix l'usage de processus est une bonne solution dans un premier choix, car ce système dispose de primitives (API) bien rodées pour les gérer, en particulier fork(), vfork() et rfork().
Néanmoins, comme le paragraphe suivant le rappelle, l'usage de processus fils n'est pas la panacée, car cette solution comporte des désagréments.
Deux autres voies existent, non toujours valables partout et dans tous les cas de figure. La première passe par l'usage de processus légers ou « threads » (paragraphe 2.3), la deuxième par l'usage du signal SIGIO qui autorise ce que l'on nomme la programmation asynchrone (paragraphe 2.4).
Pour conclure, il faut préciser que des tâches esclaves ou concourantes peuvent s'exécuter dans un ordre aléatoire, mais pas nécessairement en même temps. Cette dernière caractéristique est celle des tâches parallèles. Autrement dit, les tâches parallèles sont toutes concourantes, mais l'inverse n'est pas vrai. Concrètement il faut disposer d'une machine avec plusieurs processeurs pour avoir, par exemple, des processus (ou des « threads kernel », si elles sont supportées) qui s'exécutent vraiment de manière simultanée donc sur des processeurs différents. Sur une architecture monoprocesseur, les tâches ne peuvent être que concourantes !
15-2-2. fork, vfork et rfork▲
Il ne s'agit pas ici de faire un rappel sur la primitive fork() examinée dans le cadre du cours sur les primitives Unix, mais d'examiner l'incidence de ses propriétés sur l'architecture des serveurs.
Le résultat du fork() est la création d'un processus fils qui ne diffère de son père que par les points suivants :
- Le code de retour de fork : 0 pour le fils, le pid du fils pour le père ;
- Le numéro de processus (pid) ainsi que le numéro de processus du processus père (ppid) ;
- Les compteurs de temps (utime, stime...) qui sont remis à zéro ;
- Les verrous (flock) qui ne sont pas transmis
- Les signaux en attente non transmis également.
Tout le reste est doublonné, notamment la « stack » et surtout la « heap » qui peuvent être très volumineuses et donc rendre cette opération pénalisante, voire quasi rédhibitoire, sur un serveur très chargé (des milliers de processus et de connexions réseaux).
Si le but du fork dans le processus fils est d'effectuer un exec immédiatement, alors il est très intéressant d'utiliser plutôt le vfork. Celui-ci ne fait que créer un processus fils sans copier les données. En conséquence, durant le temps de son exécution avant le exec le fils partage strictement les mêmes données que le père (à utiliser avec précaution). Jusqu'à ce que le processus rencontre un exit ou un exec, le processus père reste bloqué (le vfork ne retourne pas).
En allant plus loin dans la direction prise par vfork, le rfork(184) autorise la continuation du processus père après le fork, la conséquence est que deux processus partagent le même espace d'adressage simultanément. L'argument d'appel du rfork permet de paramétrer ce qui est effectivement partagé ou non. RFMEM, le principal d'entre eux, indique au noyau que les deux processus partagent tout l'espace d'adressage.
Si cette dernière primitive est très riche de potentialités(185), elle est également délicate à manipuler : deux (ou plus) entités logicielles exécutant le même code et accédant aux mêmes données sans précaution particulière vont très certainement converger vers de sérieux ennuis de fonctionnement si le déroulement de leurs opérations n'est pas rigoureusement balisé.
En effet, le souci principal de ce type de programme multientité est de veiller à ce qu'aucune de ses composantes ne puisse changer les états de sa mémoire simultanément. Autrement dit, il faut introduire presque obligatoirement un mécanisme de sémaphore qui permette à l'une des entités logicielles de verrouiller l'accès à telle ou telle ressource mémoire pendant le temps nécessaire à son usage.
Cette opération de « verrouillage » elle-même pose problème, parce que les entités logicielles peuvent s'exécuter en parallèle (architecture multiprocesseur) et donc il est indispensable que l'acquisition du sémaphore qui protège une ressource commune soit une opération atomique, c'est-à-dire qui s'exécute en une fois, sans qu'il y ait possibilité que deux (ou plus) entités logicielles tentent avec succès de l'acquérir. C'est toute la problématique des mutex(186).
15-2-3. Processus l√©gers, les ¬´¬†threads¬†¬ª▲
Les processus légers ou « threads » sont une idée du milieu des années 80. La norme Posix a posé les bases de leur développement durable en 1995 (Posix 1.c), on parle dans ce cas des pthreads.
L'idée fondatrice des threads est de ne pas faire de fork mais plutôt de permettre le partage de l'espace d'adressage à autant de contextes d'exécution du même code(187) que l'on souhaite.
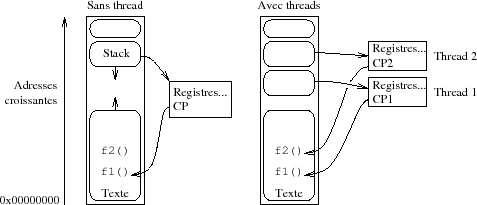
Au lieu de créer un nouveau processus on crée une nouvelle thread, ce qui revient (en gros) à ajouter un nouveau contexte d'exécution sur la pile système dans le processus. L'usage de mutex (cf. paragraphe 2.2) est fortement recommandé pour sérialiser les accès aux « sections critiques » du code.
Sur une machine ayant une architecture monoprocesseur, le premier type de threads est suffisant, mais dès que la machine est construite avec une architecture smp(188) ou cmt(189) (ce qui est de plus en plus le cas avec la banalisation des configurations à plusieurs processeurs chacun étant lui-même composé de plusieurs cœurs) l'usage de threads gérables par le noyau devient beaucoup plus intéressant, car il utilise au mieux les ressources de la machine : un même processus pourrait avoir deux threads, une s'exécutant sur chacun des deux processeurs (ou plus bien entendu, s'il y a plus de processeurs).
Le principe étant posé, on distingue plusieurs familles d'implémentation.
D'un côté il y a les threads « user land » c'est-à-dire qui sont complètement gérées par le processus utilisateur et de l'autre les threads « kernel », qui sont gérées par le noyau. Ces dernières threads sont supportées par les constructeurs de machines à architectures parallèles, traditionnellement Sun (Solaris), Ibm (Aix), et Compaq (ex Digital, avec True64) et plus récemment Hewlett-Packard avec la version 11.xx d'HP-UX. Le problème est très complexe et chaque constructeur développe ses propres stratégies.
Du côté des OS libres le problème a stagné un peu pendant des années, car il monopolise beaucoup de programmeurs de haut niveau, non toujours disponibles pour des tâches au long court... Néanmoins la famille des BSD (FreeBSD et NetBSD principalement) bénéficie depuis peu d'une gestion opérationnelle des threads.
Les threads Linux utilisent rfork qui est simple et très efficace. Cette approche n'est pas satisfaisante, car chaque thread est exécutée dans un processus différent (pid différent donc) ce qui est contraire aux recommandations POSIX, d'une part, et d'autre part ne permet pas d'utiliser les règles de priorité définies également par POSIX. Une application avec un grand nombre de threads prend l'avantage sur les autres applications par le fait qu'elle consomme en temps cumulé bien plus que les autres processus monothread.
Les threads de FreeBSD sont devenues très efficaces et performantes depuis la version 7 du système, à l'issue d'un travail de longue haleine dont l'historique se trouve sur cette page :
- http://www.freebsd.org/smp/.
Conclusion :
- Les threads user land ne s'exécutent que sur un seul processeur quelle que soit l'architecture de la machine qui les supporte. Sur une machine de type smp/cmt il faut que le système d'exploitation supporte les threads kernel pour qu'un même processus puisse avoir des sous-tâches sur tous les processeurs existants.
15-2-4. Programmation asynchrone▲
Les paragraphes qui précèdent utilisent un processus ou une thread pour pouvoir effectuer au moins deux tâches simultanément : écouter le réseau et traiter une (ou plusieurs) requête(s). Dans le cas d'un serveur peu sollicité, il est tout à fait envisageable de mettre en œuvre une autre technique appelée « programmation asynchrone ».
La programmation asynchrone s'appuie sur l'usage du signal, SIGIO (SIGPOLL sur système V), ignoré par défaut, qui prévient le processus d'une activité sur un descripteur.
La gestion des entrées/sorties sur le descripteur en question est alors traitée comme une exception, par un « handler » de signaux.
Le signal SIGIO est ignoré par défaut, il faut demander explicitement au noyau de le recevoir, à l'aide d'un appel à la primitive fcntl. Une fois activé, il n'est pas reçu pour les mêmes raisons selon le protocole employé :
- UDP :
- arrivée d'un paquet pour la socket,
- une erreur ;
- TCP :
- une demande de connexion (attente sur un accept) qui arrive,
- une déconnexion,
- une demi-déconnexion (shutdown),
- arrivée de données sur une socket,
- fin de l'émission de données (buffer d'émission vide) sur une socket,
- une erreur.
Où l'on voit que cette technique, du moins en TCP, ne peut être envisagée pour que pour des serveurs peu sollicités. Un trop grand nombre d'interruptions possibles nuit à l'efficacité du système (changements de contexte). De plus la distinction entre les causes du signal est difficile à faire, donc ce signal en TCP est quasi inexploitable.
Conclusion :
- La dénomination « programmation asynchrone » basée seulement sur l'usage du signal SIGIO (versus SIGPOLL) est abusive. Pour être vraiment asynchrones, ces opérations de lecture et d'écriture ne devraient pas être assujetties au retour des primitives read ou write(190). Cette technique permet l'écriture du code de petits serveurs basée sur le protocole UDP (en TCP les causes de réception d'un tel signal sont trop nombreuses) sans fork ni thread.
15-2-5. La primitive select▲
Un serveur qui a la charge de gérer simultanément plusieurs sockets (serveur multiprotocole par exemple, comme inetd...) se trouve par construction dans une situation où il doit examiner en même temps plusieurs descripteurs (il pourrait s'agir aussi de tubes de communication).
Il est absolument déconseillé dans cette situation de faire du polling.
Cette activité consisterait à examiner chaque descripteur l'un après l'autre, dans une boucle infinie qui devrait être la plus rapide possible pour être la plus réactive possible face aux requêtes entrantes. Sous Unix, cette opération entraîne une consommation exagérée des ressources CPU, au détriment des autres usagers et services.
La primitive select (4.3 BSD) surveille un ensemble de descripteurs, si aucun n'est actif le processus est endormi et ne consomme aucune ressource CPU. Dès que l'un des descripteurs devient actif (il peut y en avoir plusieurs à la fois) le noyau réveille le processus et l'appel de select rend la main à la procédure appelante avec suffisamment d'information pour que celle-ci puisse identifier quel(s) descripteur(s) justifie(nt) son réveil !
#include <sys/types.h>
#include <sys/time.h>
int select (int maxfd, fd_set *readfs,
fd_set *writefs,
fd_set *exceptfs,
struct timeval *timeout) ;
FD_ZERO(fd_set *fdset) ; /* Tous les bits a zero. */
FD_SET(int fd, fd_set *fdset) ; /* Positionne 'fd' dans 'fdset' */
FD_CLR(int fd, fd_set *fdset) ; /* Retire 'fd' de 'fdset' */
FD_ISSET(int fd, fd_set *fdset) ; /* Teste la présence de 'fd' */
struct timeval /* Cf "time.h" */
{
long tv_sec ; /* Nombre de secondes. */
long tv_usec ; /* Nombre de microsecondes. */
} ;Le type fd set est décrit dans <sys/types.h>, ainsi que les macros FD XXX.
Le prototype de select est dans <sys/time.h>.
La primitive select examine les masques readfs, writefs et exceptfs et se comporte en fonction de timeout :
- si timeout est une structure existante (pointeur non nul), la primitive retourne immédiatement après avoir testé les descripteurs. Tous les champs de timeout doivent être à 0 (« polling » dans ce cas) ;
- si timeout est une structure existante (pointeur non nul), et si ses champs sont non nuls, select retourne quand un des descripteurs est prêt, et en tout cas jamais au-delà de la valeur précisée par timeout (cf MAXALARM dans <sys/param.h>) ;
- si timeout est un pointeur NULL, la primitive est bloquante jusqu'à ce qu'un descripteur soit prêt (ou qu'un signal intervienne).
Remarque : select travaille au niveau de la microseconde, ce que ne fait pas sleep (seconde), d'où un usage possible de timer de précision.
- readfs descripteurs à surveiller en lecture.
- writefs descripteurs à surveiller en écriture.
- exceptfs ce champ permet de traiter des événements exceptionnels sur les descripteurs désignés. Par exemple :
- données out-of-band sur une socket ;
- contrôle du statut sur un pseudotty maître.
maxfd prend à l'appel la valeur du plus grand descripteur à tester, plus un. Potentiellement un système BSD (4.3 et versions suivantes) permet d'examiner jusqu'à 256 descripteurs.
À l'appel, le programme précise quels sont les descripteurs à surveiller dans readfs, writefs et exceptfs.
Au retour, la primitive précise quels sont les descripteurs qui sont actifs dans les champs readfs, writefs et exceptfs. Il convient donc de conserver une copie des valeurs avant l'appel si on veut pouvoir les réutiliser ultérieurement. La primitive renvoie -1 en cas d'erreur (à tester systématiquement) ; une cause d'erreur classique est la réception d'un signal (errno==EINTR).
La macro FD ISSET est utile au retour pour tester quel descripteur est actif et dans quel ensemble.
Le serveur de serveurs inetd est un excellent exemple d'utilisation de la primitive.
15-2-6. La primitive poll▲
La primitive poll (System V) permet la même chose que la primitive select, mais avec une approche différente.
#include <poll.h>
int
poll(struct pollfd *fds, unsigned int nfds, int timeout);
struct pollfd {
int fd ; /* Descripteur de fichier */
short events ; /* Evenements attendus */
short revents ; /* Evenements observes */
} ;La primitive retourne le nombre de descripteurs rendus disponibles pour effectuer des opérations d'entrée/sortie. -1 indique une condition d'erreur. 0 indique l'expiration d'un délai (« time-out »).
- fds est un pointeur sur la base d'un tableau de nfds structures du type struct pollfd.
- Les champs events et revents sont des masques de bits qui paramètrent respectivement les souhaits du programmeur et ce que le noyau retourne. On utilise principalement :
- POLLIN,
- POLLOUT,
- POLLERR,
- POLLHUP,
- POLLIN,
- POLLOUT,
- POLLERR,
- POLLHUP.
- nfds taille du vecteur.
- timeout est un compteur de millisecondes qui précise le comportement de poll :
- le nombre de millisecondes est positif strictement. Quand le temps prévu est écoulé, la primitive retourne dans le code de l'utilisateur même si aucun événement n'est intervenu,
- le nombre de millisecondes est INFTIM (-1), la primitive est bloquante,
- 0. La primitive retourne immédiatement.
On s'aperçoit immédiatement que la valeur du paramètre de timeout n'est pas compatible ni en forme ni en comportement entre select et poll.
15-3. Fonctionnement des daemons▲
Sous Unix les serveurs sont implémentés le plus souvent sous forme de daemons(191). La raison principale est que ce type de processus est le plus adapté à cette forme de service, comme nous allons l'examiner.
15-3-1. Programmation d'un daemon▲
Les daemons sont des processus ordinaires, mais :
- ils ne sont pas rattachés à un terminal particulier (ils sont en « arrière-plan ») ;
- ils s'exécutent le plus souvent avec les droits du « superutilisateur », voire, mieux, sous ceux d'un pseudoutilisateur sans mot de passe ni shell défini ;
- ils sont le plus souvent lancés au démarrage du système, lors de l'exécution des shell-scripts de configuration (par exemple à partir de /etc/rc) ;
- ils ne s'arrêtent en principe jamais (sauf bien sûr avec le système !).
La conception d'un daemon suit les règles suivantes :
- Exécuter un fork, terminer l'exécution du père et continuer celle du fils qui est alors adopté par init (traditionnellement c'est le processus N° 1). Le processus fils est alors détaché du terminal, ce que l'on peut visualiser avec un ps -auxw (versus ps -edalf sur un système V) en examinant la colonne TT : elle contient ? ? ;
- Appeler la primtive setsid pour que le processus courant devienne « leader » de groupe (il peut y avoir un seul processus dans un groupe) ;
- Changer de répertoire courant, généralement la racine (/) ou tout autre répertoire à la convenance de l'application ;
- Modifier le masque de création des fichiers umask = 0 pour que le troisième argument de open ne soit pas biaisé par la valeur du umask lorsque cette primitive sert aussi à créer des fichiers ;
- Fermer tous les descripteurs devenus inutiles, et en particulier 0, 1 et 2 (entrée et sorties standards n'ont plus de sens pour un processus détaché d'un terminal).
Le source ci-après est un exemple de programmation de daemon, les appels à la fonction syslog font référence à un autre daemon nommé syslogd que nous examinons au paragraphe suivant.
/* $Id: diable.c 92 2009-02-12 17:39:44Z fla $
*
* Diablotin : exemple de démon miniature...
*/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <syslog.h>
#include <errno.h>
int
main()
{
switch (fork()) {
case -1 : /* erreur du "fork". */
perror("fork") ;
exit (1) ;
case 0 : /* Le futur "demon". */
(void)printf("Je suis infernal, je me transforme en demon !\n") ;
(void)setsid() ; /* Devenir chef de groupe. */
(void)chdir("/") ; /* Repertoire de travail. */
(void)umask(0) ;
(void)close(0) ;
(void)close(1) ;
(void)close(2) ;
openlog("diablotin",LOG_PID|LOG_NDELAY,LOG_USER) ;
syslog(LOG_INFO,"Attention, je suis un vrai 'daemon'...\n") ;
(void)sleep(1) ;
(void)syslog(LOG_INFO,"Je me tue !\n") ;
closelog() ;
exit(EX_OK) ;
default :
exit(EX_OK) ;
}
}15-3-2. Daemon syslogd▲
Du fait de leur fonctionnement détaché d'un terminal, les daemons ne peuvent plus délivrer directement de message par les canaux habituels (perror...). Pour pallier cette déficience, un daemon est spécialisé dans l'écoute des autres daemons (écoute passive :), il s'agit de syslogd(192).
Pour dialoguer avec ce daemon un programme doit utiliser les fonctionnalités que le lecteur trouvera très bien décrites dans « man syslog », sinon le paragraphe 3.4 en donne un aperçu rapide.
La figure XIV.3 suivante schématise le circuit de l'information dans le cas d'une utilisation de syslogd.
Le fichier /etc/syslog.conf est le fichier standard de configuration du daemon syslogd. Il est constitué de lignes de deux champs : un déclencheur (selector) et une action. Entre ces deux champs un nombre quelconque de tabulations.
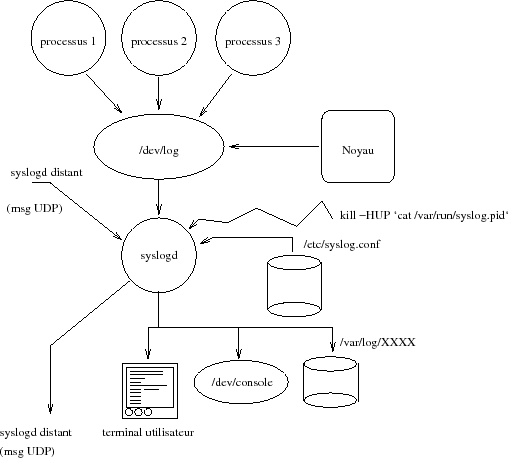
Si les conditions du déclencheur sont remplies, l'action est exécutée, plus précisément :
le déclencheur est un filtre qui associe un type de daemon avec un niveau de message. Par exemple mail.debug signifie les messages de niveau DEBUG pour le système de routage du courrier ;
les mots-clefs possibles pour le type de daemon sont auth, authpriv, cron, daemon, kern, lpr, mail, news, syslog, user, uucp, et local0 à local7. Une étoile (*) à la place, signifie n'importe quel mot-clef ;
le niveau de message est l'un des mots-clefs suivants : emerg, alert, crit, err, warning, notice, et debug. Une étoile (*) signifie n'importe lequel. Un point (.) sépare les deux parties du filtre, comme dans mail.debug.
Dans les syslog plus évolués, l'administrateur a la possibilité de dérouter tous les messages contenant un nom de programme ( !nom du prog) ou un nom de machine (+nom de machine).
L'action est soit :
- un fichier désigné par un chemin absolu, comme /var/log/syslog ;
- une liste de logins d'utilisateurs, comme root, fla... ;
- un nom de machine distante (@machine.domaine.fr) ;
- tous les utilisateurs connectés avec une étoile.
15-3-3. Fichier syslog.conf▲
Exemple de fichier /etc/syslog.conf :
*.err;kern.debug;auth.notice;mail.crit /dev/console
*.notice;kern.debug;lpr,auth.info;mail.crit /var/log/messages
mail.info /var/log/maillog
lpr.info /var/log/lpd-errs
cron.* /var/cron/log
*.err root
*.notice;auth.debug root
*.alert root
*.emerg *
*.info |/usr/local/bin/traitinfo
!diablotin
*.* /var/log/diablotin.logRésultat de l'exécution de diablotin sur la machine glups, et dans le fichier /var/log/diablotin.log :
...
Jan 27 18:52:02 glups diablotin[20254]: Attention, je suis un vrai 'daemon'...
Jan 27 18:52:03 glups diablotin[20254]: Je me tue !15-3-4. Fonctions syslog▲
Les prototypes et arguments des fonctions :
#include <syslog.h>
void openlog(const char *ident, int logopt, int facility) ;
void syslog(int priority, const char *message, ...) ;
void closelog(void) ;Comme dans l'exemple de « diablotin », un programme commence par déclarer son intention d'utiliser le système de log en faisant appel à la fonction openlog :
- logopt donne la possibilité de préciser où le message est envoyé et dans quelle condition ;
- facility est l'étiquette par défaut des futurs messages envoyés par syslog ;
- logopt description
- LOG CONS écriture sur /dev/console,
- LOG NDELAY ouverture immédiate de la connexion avec syslogd,
- LOG PERROR écriture d'un double du message sur stderr,
- LOG PID Identifier chaque message avec le pid ;
- facility description
- LOG AUTH services d'authentification,
- LOG AUTHPRIV idem ci-dessus,
- LOG CRON le daemon qui gère les procédures batch,
- LOG DAEMON tous les daemons du système, comme gated,
- LOG KERN messages du noyau,
- LOG LPR messages du gestionnaire d'imprimante,
- LOG MAIL messages du gestionnaire de courrier,
- LOG NEWS messages du gestionnaire de « news »,
- LOG SYSLOG messages du daemon syslogd lui-même,
- LOG USER messages des processus utilisateur (defaut),
- LOG UUCP messages du système de transfert de fichiers,
- LOG LOCAL0 réservé pour un usage local.
Puis chaque appel à la fonction syslog est composé d'un message (généré par l'application) et d'un code de priorité, composé d'un niveau d'urgence précisé par le tableau ci-dessous (niveaux décroissants) et d'une étiquette optionnelle, prise dans le tableau ci-dessus ; elle prime alors sur celle précisée lors du openlog.
- priority description
- LOG EMERG une condition de « panic system »,
- LOG ALERT intervention immédiate requise,
- LOG CRIT problèmes de matériels,
- LOG ERR erreurs,
- LOG WARNING messages d'avertissement,
- LOG NOTICE messages qui ne sont pas des erreurs,
- LOG INFO informations sans conséquence,
- LOG DEBUG messages pour le débogage,
- LOG EMERG une condition de « panic system »,
- LOG ALERT intervention immédiate requise,
- LOG CRIT problèmes de matériel,
- LOG ERR erreurs,
- LOG WARNING messages d'avertissement,
- LOG NOTICE messages qui ne sont pas des erreurs,
- LOG INFO informations sans conséquence,
- LOG DEBUG messages pour le débogage.
Enfin le closelog matérialise la fin d'utilisation de ce système dans le code.
15-4. Exemple de ¬´¬†daemon¬†¬ª inetd▲
Dans cette partie nous allons étudier un serveur de serveurs nommé inetd qui est un très bel exemple pour conclure ce chapitre.
Ce chapitre pourra se prolonger par la lecture du code source C d'inetd.
15-4-1. Pr√©sentation de inetd▲
Sous Unix, on peut imaginer facilement que chacun des services réseau offerts soient programmés comme un daemon, avec une ou plusieurs sockets, chacun surveillant son ou ses ports de communication.
Un tel fonctionnement existe, généralement repéré par le vocabulaire « stand alone ». Avec cette stratégie, chaque service comme « ftp », « rlogin », ou encore « telnet » fait l'objet d'un processus daemon (« daemon »).
Avant la version 4.3 de BSD, c'est comme cela que tous les services fonctionnaient.
Le problème est que pour faire fonctionner les services de base du réseau on devait maintenir en mémoire (primaire en « ram » ou secondaire sur la zone de « swap ») un grand nombre de processus souvent complètement inutiles à un instant donné, simplement au cas où...
L'inconvénient de cette stratégie est la consommation importante de ressources surtout avec le nombre croissant des services réseau « de base ».
De plus, on peut remarquer que lancés au démarrage de la machine, tous ces processus effectuent des opérations similaires (cf. 3), seuls diffèrent les traitements propres aux serveurs eux-mêmes c'est-à-dire ceux qui relèvent du protocole de l'application.
La version 4.3 de BSD a apporté une simplification en introduisant une nouvelle notion, celle de serveur de serveurs : « The Internet superserver - inetd ». C'est un daemon que peuvent utiliser tous les serveurs TCP/UDP.
Inetd fournit essentiellement deux services principaux :
- Il permet à un seul processus (celui d'inetd) d'attendre de multiples demandes de connexions au lieu d'avoir un processus par type de connexion. Cette stratégie réduit d'autant le nombre de processus ;
- Il simplifie l'écriture des serveurs eux-mêmes, puisqu'il gère toute la prise en charge de la connexion. Les serveurs lisent les requêtes sur leur entrée standard et écrivent la réponse sur leur sortie standard.
Inetd est un serveur parallèle en mode connecté ou datagramme. De plus il combine des caractéristiques particulières, puisqu'il est également multiprotocole et multiservice. Un même service peut y être enregistré et accessible en udp comme en tcp. Bien sûr cela sous-entend que le programmeur de ce service a prévu ce fonctionnement.
Le prix à payer pour une telle souplesse est élevé, inetd invoque fork puis exec pour pratiquement tous les services qu'il offre (cf. lecture de code).
Sur les Unix à architecture Berkeley, inetd est invoqué au démarrage de la machine, dans les scripts de lancement, /etc/rc par exemple. Dès le début de son exécution il se transforme en daemon (cf. paragraphe IV.5.3) et lit un fichier de configuration généralement nommé /etc/inetd.conf. Ce fichier est en ASCII, il est lisible normalement par tous, cependant, sur certains sites et pour des raisons de sécurité, il peut ne pas l'être.
La figure XIV.04 montre l'architecture générale (très simplifiée) de fonctionnement.
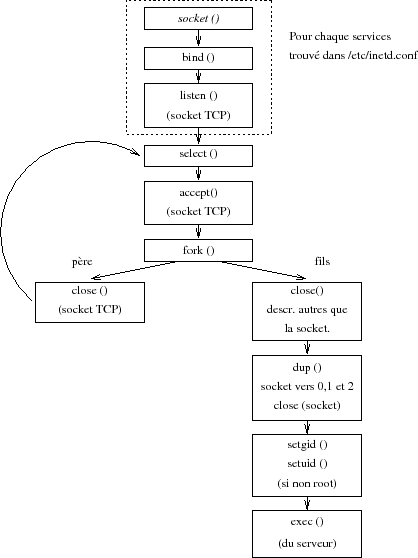
Le fichier /etc/inetd.conf est organisé de la manière suivante :
- un # en début de ligne indique un commentaire, comme pour un shellscript ;
- les lignes vides ne sont pas prises en compte ;
- les lignes bien formées sont constituées de sept champs. Chaque ligne bien formée décrit un serveur.
Description des champs :
- Le nom du service, qui doit également se trouver dans le fichier /etc/services. C'est grâce à lui que inetd connait le numéro de port à employer ;
- Le type de socket, connectée (stream) ou non (dgram) :
- Le protocole qui doit être tcp ou udp et doit en tout cas se trouver dans le fichier /etc/protocols. Ce dernier fichier donne une correspondance numérique aux différents protocoles ;
- wait ou nowait suivant que le serveur est itératif ou parallèle ;
- Le nom du propriétaire (pour les droits à l'exécution). Le plus souvent c'est root, mais ce n'est pas une règle générale ;
- Le chemin absolu pour désigner l'exécutable du serveur ;
- Les arguments transmis à cet exécutable lors du exec, il y en a 20 au maximum dans les implémentations Berkeley de inetd (certaines réécritures, comme celle d'HP, limitent ce nombre).
15-5. Exemple de code serveur▲
L'exemple qui suit est le code en langage C d'un serveur d'écho multiprotocole, c'est-à-dire qui fonctionne avec TCP et UDP simultanément sur un même numéro de port pour les deux protocoles. La contrainte est que l'usage du serveur pour l'un des protocoles n'empêche pas l'accès au serveur pour l'autre protocole.
Ce serveur offre également le choix de travailler en mode itératif ou en mode parallèle. Cette alternative est pilotée à partir de la ligne de commande, donc au lancement du serveur (option -n ou -w).
Il est intéressant de remarquer que le cœur du serveur est construit autour de l'usage de la primitive select pour gérer l'écoute sur des sockets multiples, ici au nombre de deux.
D'un point de vue plus général ce serveur reprend l'architecture globale du serveur de serveur inetd mais le simplifiant à l'extrême, c'est-à-dire sans gestion du fichier de configuration, et sans gestion des limites.
15-5-1. Guide de lecture du source serv2prot.c▲
Le source de cet exemple se trouve à l'annexe A.
Le programme 'serv2prot' le lance avec les options suivantes :
- -p numéro du port ;
- -n mode concourant ;
- -w mode itératif.
- la fonction 'main' (ligne 64 à 178) contient la structure principale du programme ;
- Ligne 77 boucle de lecture des arguments de la ligne de commande. L'option -p a besoin d'un argument (le # de port) dont la lecture est effectuée ligne 80 (usage de la fonction atoi pour transformer la chaîne de caractères en entier) ;
- Ligne 102 ouverture d'une socket UDP utilisant le port nport lu sur la ligne de commande ;
- Ligne 103 même chose que ligne 102, mais avec une socket TCP ;
- Ligne 104 c'est le majorant de sudp et stcp (pour select) ;
- Ligne 106 mise à zéro de tous les bits de la variable lect (fd set) ;
- Ligne 107 ajout du descripteur udp ;
- Ligne 108 ajout du description tcp ;
- Ligne 110 mise en place de la prise en compte des signaux de type SIGCHLD. C'est la fonction PasDeZombi qui est appelée ;
- Ligne 111 mise en place de la prise en compte du signal de fin, ici un SIGHUP. Appel de la fonction FinCanonique dans ce cas ;
- Ligne 113 entrée de la boucle principale et infinie du serveur ;
- Ligne 114 recopie dans alire des descripteurs à surveiller en lecture ;
- Ligne 116 appel de la primitive select, sans time-out, donc bloquante indéfiniment (c'est-à-dire jusqu'à l'arrivée d'une demande de cnx) ;
- Ligne 118 si on arrive à cette ligne c'est qu'un signal a interrompu la primitive. Le résultat du test est VRAI si la primitive a été interrompue par un signal (par exemple SIGCHLD), le 'continue' permet de retourner à l'évaluation de la condition de sortie de boucle immédiatement. Sinon il s'agit d'une erreur non contournable, affichage d'un message et sortie.
- Ligne 124 select a renvoyé le nombre de descripteurs qui justifient son retour en « user land ». Ce nombre est un ou deux au maximum (seulement deux sockets à surveiller). On boucle jusqu'à épuisement du nombre de descripteurs à examiner ;
- Ligne 125 FD ISSET permet de tester si la socket stcp est active. Si oui alors on passe à la ligne 127 ;
- Ligne 127 appel de accept pour la socket tcp. Il faut noter qu'on ne tient pas compte de l'adresse du client réseau (deuxième et troisième arguments). sock contient le descripteur de la socket vers le client.
- Ligne 133 idem que ligne 125, mais pour la socket UDP ;
- Ligne 138 usage de la primitive getpeername pour obtenir l'adresse de la socket du client (adresse IP + numéro de port) ;
- Ligne 142 usage des fonctions inet ntoa et ntohs pour afficher l'adresse IP et le port du client qui se connecte ;
- Ligne 144 il s'agit d'une étiquette, point d'entrée du goto qui se situe ligne 148 ;
- Ligne 145 on tente de lancer le service demandé, à exécuter dans un processus fils ;
- Ligne 147 en cas d'erreur, si le fork a été interrompu par un signal, par exemple eaSIGCHLD, on effectue un saut inconditionnel à l'étiquette retry signalée ligne 144. Sinon c'est une vraie erreur à traiter ;
- Ligne 151 il s'agit du code exécuté dans le processus fils. intcp==VRAI s'il s'agit de la socket TCP. Fermeture des sockets devenues inutiles (c'est sock qui est utile) ;
- Ligne 155 invocation la fonction qui gère l'écho en TCP ;
- Ligne 158 fermeture de la socket TCP inutile. La socket UDP est indispensable ;
- Ligne 159 invocation de la fonction qui gère l'écho en UDP ;
- Ligne 161 sortie du code pour les processus fils ;
- Ligne 162 il s'agit du code exécuté dans le processus père. Si le mode de fonctionnement est itératif, la socket en question (TCP vs UDP) doit être retirée des descripteurs à surveiller. Elle y sera remise lorsque le processus fils qui traite la session en cours sera terminé (cf. fonction PasDeZombi ligne 184) ;
- Ligne 165 si on vient de traiter la socket TCP, on fait le ménage avant la prochaine boucle : fermeture de sock devenu inutile, retrait de stcp de alire et conservation d'une trace du pid ;
- Ligne 175 on décrémente le nombre de descripteurs à examiner ;
- Ligne 177 fin de la boucle principale commencée ligne 124 ;
- Ligne 171 conservation du pid du fils UDP et suppression de sudp de alire. La fonction PasDeZombi est le handler pour les signaux de type SIGCHLD, envoyés par le noyau au processus père dès que l'un de ses fils fait exit ;
- Ligne 194 usage de la primitive wait3 qui permet de faire une attente non bloquante (c'est justifié dans la mesure où on a reçu un SIGCHLD) de la mort d'un fils. Chaque appel renvoie le pid d'un processus fils mort, s'il n'y a plus de processus fils mort à examiner le retour est négatif. C'est la condition de sortie de boucle ;
- Ligne 195 si on entre dans ce test, la variable pid contient le pid du fils terminé et le mode de fonctionnement est itératif ;
- Ligne 197 pour la socket TCP on remet stcp dans les descripteurs à surveiller ;
- Ligne 202 pour la socket UDP on remet sudp dans les descripteurs à surveiller ;
- Ligne 207 certains OS ont besoin que l'on repositionne le handler de signaux à chaque réception du signal. Ce n'est pas le cas des BSD ;
- Ligne 215 FinCanonique est appelée sur réception du signal de fin SIGHUP. C'est la sortie inconditionnelle du programme ;
- Les fonctions OuvrirSocketUDP et OuvrirSocketTCP sont une reformulation de ce qui a déjà été examiné précédemment ;
- Les fonctions TraiterTCP et TraiterUDP ne présentent pas de difficulté de lecture.
15-6. Bibliographie▲
Pour la partie architecture/configuration des serveurs :
- W. Richard Stevens - « Unix Network Programming » - Prentice All - 1990
- W. Richard Stevens - « Unix Network Programming » - Volume 1 & 2 - Second edition - Prentice All - 1998
- W. Richard Stevens - « Advanced Programming in the UNIX Environment » - Addison-Wesley - 1992
- W. Richard Stevens - Bill Fenner - Andrew M. Rudoff - « Unix Network Programming » - Third edition, volume 1 - Prentice All - 2004
- Douglas E. Comer - David L. Stevens - « Internetworking with TCP/IP - Volume III » (BSD Socket version) - Prentice All - 1993
- Stephen A. Rago - « Unix System V Network Programming » - Addison-Wesley - 1993
- Man Unix de inetd, syslog, syslogd et syslog.conf.
Pour la programmation des threads :
- David R. Butenhof - « Programming with POSIX Threads » - Addison-Wesley - 1997
- Bradford Nichols, Dirsk Buttlar & Jacqueline Proulx Farell - « Pthreads programming » - O'Reilly & Associates, Inc. - 1996
Et pour aller plus loin dans la compréhension des mécanismes internes :
- McKusick, Bostik, Karels, Quaterman - « The Design and implementation of the 4.4 BSD Operating System » - Addison Wesley - 1996
- Jim Mauro, Richard McDougall - « Solaris Internals » - Sun Microsystems Press - 2001
- Uresh Vahalia - « Unix Internals, the new frontiers » - Prentice Hall - 1996