


5. Protocole IP▲
5-1. Datagramme IP▲
IP est l'acronyme de ﺡ،ﺡ Internet Protocolﺡ ﺡﭨ, il est dﺣ۸fini dans la RFC 791 et a ﺣ۸tﺣ۸ conﺣ۶u en 1980 pour remplacer NCP (ﺡ،ﺡ Network Control Protocolﺡ ﺡﭨ), le protocole de l'Arpanet.
Presque trente ans aprﺣ۷s sa premiﺣ۷re implﺣ۸mentation, ses limitations se font de plus en plus pﺣ۸nalisantes pour les nouveaux usages sur les rﺣ۸seaux. Avant de le jeter aux orties, posons-nous la question de qui pouvait prﺣ۸voir ﺣ cette ﺣ۸poque oﺣﺗ moins de mille ordinateurs ﺣ۸taient reliﺣ۸s ensemble que trois dﺣ۸cennies plus tard des dizaines de millions d'hﺣﺑtes l'utiliseraient comme principal protocole de communicationﺡ ?
Sa longﺣ۸vitﺣ۸ est donc remarquable et il convient de l'analyser de prﺣ۷s avant de pouvoir le critiquer de maniﺣ۷re constructive.
5-1-1. Structure de l'entﺣ۹te▲
Les octets issus de la couche de transport et encapsulﺣ۸s ﺣ l'aide d'un entﺣ۹te IP avant d'ﺣ۹tre propagﺣ۸s vers la couche rﺣ۸seau (Ethernet par exemple), sont collectivement nommﺣ۸s ﺡ،ﺡ datagramme IPﺡ ﺡﭨ, datagramme Internet ou datagramme tout court. Ces datagrammes ont une taille maximale liﺣ۸e aux caractﺣ۸ristiques de propagation du support physique, c'est le ﺡ،ﺡ Maximum Transfer Unitﺡ ﺡﭨ ou MTU.
Quelques caractﺣ۸ristiques en vrac du protocole IPﺡ :
- IP est le support de travail des protocoles de la couche de transport, UDP, TCP et SCTPﺡ ;
- IP ne donne aucune garantie quant au bon acheminement des donnﺣ۸es qu'il envoie. Il n'entretient aucun dialogue avec une autre couche IP distante, on dit aussi qu'il dﺣ۸livre les datagrammes ﺡ،ﺡ au mieuxﺡ ﺡﭨﺡ ;
- chaque datagramme est gﺣ۸rﺣ۸ indﺣ۸pendamment des autres datagrammes mﺣ۹me au sein du transfert des octets d'un mﺣ۹me fichier. Cela signifie que les datagrammes peuvent ﺣ۹tre mﺣ۸langﺣ۸s, dupliquﺣ۸s, perdus ou altﺣ۸rﺣ۸sﺡ !
- Ces problﺣ۷mes ne sont pas dﺣ۸tectﺣ۸s par IP et donc il ne peut en informer la couche de transportﺡ ;
- les octets sont lus et transmis au rﺣ۸seau en respectant le ﺡ،ﺡ Network Byte Orderﺡ ﺡﭨ ou NBO (cf. paragraphe 1.2), quelle que soit l'architecture CPU de l'hﺣﺑteﺡ ;
- l'entﺣ۹te IP minimal fait cinq mots de quatre octets, soit 20 octets. S'il y a des options, la taille maximale peut atteindre 60 octets.
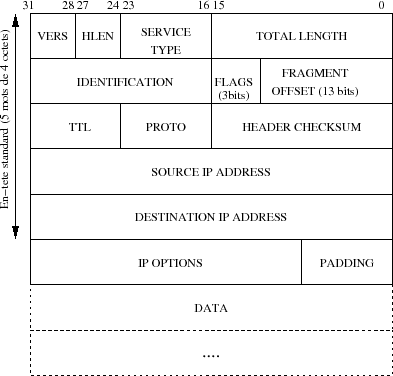
5-1-2. Network Byte Order▲
Sur la figure V.01 les bits les plus significatifs de chaque mot de quatre octets sont ﺣ gauche (31...). Ils sont d'ailleurs transmis sur le rﺣ۸seau dans cet ordre(37), c'est un standard, c'est le ﺡ،ﺡ Network Byte Orderﺡ ﺡﭨ.
Toutes les architectures de CPU ne sont pas bﺣ۱ties sur le mﺣ۹me modﺣ۷leﺡ :
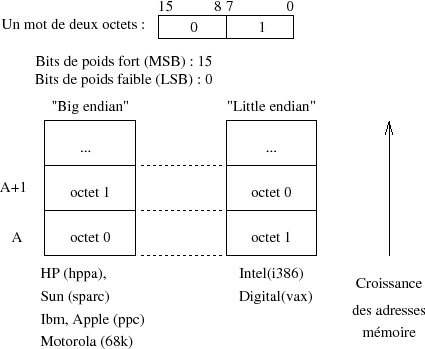
Les termes ﺡ،ﺡ Big endianﺡ ﺡﭨ et ﺡ،ﺡ Little endianﺡ ﺡﭨ indiquent quelle est la terminaison (ﺡ،ﺡ endﺡ ﺡﭨ) de deux octets que l'on ﺣ۸crit en premier, le poids fort (ﺡ،ﺡ bigﺡ ﺡﭨ), c'est aussi le sens de l'ﺣ۸criture humaine, ou le poids faible (ﺡ،ﺡ littleﺡ ﺡﭨ).
5-1-3. Description de l'entﺣ۹te▲
VERS
- Quatre bits qui spﺣ۸cifient la version du protocole IP. L'objet de ce champ est la vﺣ۸rification que l'ﺣ۸metteur et le destinataire des datagrammes sont bien en phases avec la mﺣ۹me version. Actuellement c'est la version 4 qui est principalement utilisﺣ۸e sur l'Internet, bien que quelques implﺣ۸mentations de la version 6 existent et soient dﺣ۸jﺣ en expﺣ۸rimentation(38).
HLEN
- Quatre bits qui donnent la longueur de l'entﺣ۹te en mots de quatre octets. La taille standard de cet entﺣ۹te fait cinq mots, la taille maximale faitﺡ : (23 + 22 + 21 + 20) x 4 = 60 octets(39).
TOTAL LENGTH
- Donne la taille du datagramme, entﺣ۹te plus donnﺣ۸es. S'il y fragmentation (voir plus loin) il s'agit ﺣ۸galement de la taille du fragment (chaque datagramme est indﺣ۸pendant des autres).
- La taille des donnﺣ۸es est donc ﺣ calculer par soustraction de la taille de l'entﺣ۹te.
- 16 bits autorisent la valeur 65535... La limitation vient le plus souvent du support physique (MTU) qui impose une taille plus petite, sauf sur les liaisons de type ﺡ،ﺡ hyperchannelﺡ ﺡﭨ.
TYPE OF SERVICE vs DSCP/ECN
- Historiquement dans la RFC 791 ce champ est nommﺣ۸ TYPE OF SERVICE et joue potentiellement deux rﺣﺑles selon les bits examinﺣ۸s (prﺣ۸sﺣ۸ance et type de service). Pratiquement, la prﺣ۸sﺣ۸ance ne sert plus et la RFC 1349 dﺣ۸finit quatre bits utiles sur les huit (3 ﺣ 6). Ceux-ci indiquent au routeur l'attitude ﺣ avoir vis-ﺣ -vis du datagramme.
- Par exemple, des datagrammes d'un transfert de fichier (ftp) peuvent avoir ﺣ laisser passer un datagramme repﺣ۸rﺣ۸ comme contenant des caractﺣ۷res frappﺣ۸s au clavier (session Telnet).
| 0x00 | - | Service normal | Transfert banal |
| 0x10 | bit 3,D | Minimiser le dﺣ۸lai | Session telnet |
| 0x08 | bit 4,T | Maximiser le dﺣ۸bit | Transfert ftp |
| 0x04 | bit 5,R | Maximiser la qualitﺣ۸ | ICMP |
| 0x02 | bit 6,C | Minimiser le coﺣﭨt | ﺡ،ﺡ newsﺡ ﺡﭨ (nntp) |
- L'usage de ces bits est mutuellement exclusif.
- Les nouveaux besoins de routage ont conduit l'IETF ﺣ revoir la dﺣ۸finition de ce champ dans la RFC 3168. Celle-ci partage les huit bits en deux parties, les premiers bits dﺣ۸finissent le DSCP ou ﺡ،ﺡ Differentiated Services CodePointsﺡ ﺡﭨ qui est une version beaucoup plus fine des quatre bits ci-dessus. Les deux derniers bits dﺣ۸finissent l'ECN ou ﺡ،ﺡ Explicit Congestion Notificationﺡ ﺡﭨ qui est un mﺣ۸canisme permettant de prﺣ۸venir les congestions, contrairement au mﺣ۸canisme plus ancien basﺣ۸ sur les messages ICMP de type ﺡ،ﺡ source quenchﺡ ﺡﭨ qui tente de rﺣ۸gler le flux en cas de congestion.
- Il faut noter que les protocoles de routage qui tiennent compte de l'ﺣ۸tat des liaisons (OSPF,IS-IS...) sont susceptibles d'utiliser ce champ.
- Enfin la RFC 3168 indique que ces deux ﺣ۸critures du champ ne sont pas compatibles entre elles...
IDENTIFICATION, FLAGS et FRAGMENT OFFSET
- Ces mots sont prﺣ۸vus pour contrﺣﺑler la fragmentation des datagrammes. Les donnﺣ۸es sont fragmentﺣ۸es, car les datagrammes peuvent avoir ﺣ traverser des rﺣ۸seaux avec des MTU plus petits que celui du premier support physique employﺣ۸.
- Consulter la section suivante Fragmentation IP.
TTL
- ﺡ،ﺡ Time To Liveﺡ ﺡﭨ 8 bits, 255 secondes maximum de temps de vie pour un datagramme sur le Net.
- Prﺣ۸vu ﺣ l'origine pour dﺣ۸compter un temps, ce champ n'est qu'un compteur dﺣ۸crﺣ۸mentﺣ۸ d'une unitﺣ۸ ﺣ chaque passage dans un routeur.
- Couramment la valeur de dﺣ۸part est 32 ou mﺣ۹me 64. Son objet est d'ﺣ۸viter la prﺣ۸sence de paquets fantﺣﺑmes circulant indﺣ۸finiment...
- Si un routeur passe le compteur ﺣ zﺣ۸ro avant dﺣ۸livrance du datagramme, un message d'erreur - ICMP (consultez le paragraphe 4) - est renvoyﺣ۸ ﺣ l'ﺣ۸metteur avec l'indication du routeur. Le paquet en lui-mﺣ۹me est perdu.
PROTOCOL
- Huit bits pour identifier le format et le contenu des donnﺣ۸es, un peu comme le champ ﺡ،ﺡ typeﺡ ﺡﭨ d'une trame Ethernet. Il permet ﺣ IP d'adresser les donnﺣ۸es extraites ﺣ l'une ou l'autre des couches de transport.
- Dans le cadre de ce cours, nous utiliserons essentiellement ICMP(1), IGMP(2), IP-ENCAP(4), TCP(6), UDP(17), ESP(50), AH(51), et OSPF(89).
- La table de correspondance entre le symbole et le numﺣ۸ro du protocole est prﺣ۸sente sur tout systﺣ۷me d'exploitation digne de ce nom, dans le fichier /etc/protocols.
HEADER CHECKSUM
- 16 bits pour s'assurer de l'intﺣ۸gritﺣ۸ de l'entﺣ۹te. Lors du calcul de ce ﺡ،ﺡ checksumﺡ ﺡﭨ ce champ est ﺣ 0.
- ﺣ la rﺣ۸ception de chaque paquet, la couche calcule cette valeur, si elle ne correspond pas ﺣ celle trouvﺣ۸e dans l'entﺣ۹te le datagramme est oubliﺣ۸ (ﺡ،ﺡ discardﺡ ﺡﭨ) sans message d'erreur.
SOURCE ADDRESS
- Adresse IP de l'ﺣ۸metteur, ﺣ l'origine du datagramme.
DESTINATION ADDRESS
- Adresse IP du destinataire du datagramme.
IP OPTIONS
- 24 bits pour prﺣ۸ciser des options de comportement des couches IP traversﺣ۸es et destinatrices. Les options les plus courantes concernentﺡ :
- des problﺣ۷mes de sﺣ۸curitﺣ۸,
- des enregistrements de routes,
- des enregistrements d'heure,
- des spﺣ۸cifications de route ﺣ suivre,
- ...
- Historiquement ces options ont ﺣ۸tﺣ۸ prﺣ۸vues dﺣ۷s le dﺣ۸but, mais leur implﺣ۸mentation n'a pas ﺣ۸tﺣ۸ terminﺣ۸e et la plupart des routeurs filtrants bloquent les datagrammes IP comportant des options.
PADDING
- Remplissage pour aligner sur 32 bits...
En conclusion partielle que peut-on dire du travail de la couche IPﺡ ?
- Il consiste ﺣ router les datagrammes en les acheminant ﺡ،ﺡ au mieuxﺡ ﺡﭨ, on verra plus loin de quelle maniﺣ۷re. C'est son travail principal.
- Il peut avoir ﺣ fragmenter les donnﺣ۸es de taille supﺣ۸rieure au MTU du support physique ﺣ employer.
5-1-4. Fragmentation IP - MTU▲
La couche de liaison (Couche 2 ﺡ،ﺡ Linkﺡ ﺡﭨ) impose une taille limite, le ﺡ،ﺡ Maximum Transfer Unitﺡ ﺡﭨ. Par exemple cette valeur est de 1500 pour une trame Ethernet, elle peut ﺣ۹tre de 256 avec SLIP (ﺡ،ﺡ Serial Line IPﺡ ﺡﭨ) sur liaison sﺣ۸rie (RS232...).
Dans ces conditions, si la couche IP doit transmettre un bloc de donnﺣ۸es de taille supﺣ۸rieure au MTU ﺣ employer, il y a fragmentationﺡ !
Par exemple, un bloc de 1481 octets sur Ethernet sera dﺣ۸composﺣ۸ en un datagramme de 1480 ( 1480 + 20 = 1500) et un datagramme de 1 octetﺡ !
Il existe une exception ﺣ cette opﺣ۸ration, due ﺣ la prﺣ۸sence active du bit ﺡ،ﺡ Don't Fragment bitﺡ ﺡﭨ du champ FLAGS de l'entﺣ۹te IP. La prﺣ۸sence ﺣ 1 de ce bit interdit la fragmentation dudit datagramme par la couche IP qui en aurait besoin. C'est une situation de blocage, la couche ﺣ۸mettrice est tenue au courant par un message ICMP (cf. paragraphe 4) ﺡ،ﺡ Fragmentation needed but don't fragment bit setﺡ ﺡﭨ et bien sﺣﭨr le datagramme n'est pas transmis plus loin.
5-1-4-1. Fragmentation▲
- Quand un datagramme est fragmentﺣ۸, il n'est rﺣ۸assemblﺣ۸ que par la couche IP destinatrice finale. Cela implique trois remarquesﺡ :
- la taille des datagrammes reﺣ۶us par le destinataire final est directement dﺣ۸pendante du plus petit MTU rencontrﺣ۸ﺡ ;
- les fragments deviennent des datagrammes ﺣ part entiﺣ۷reﺡ ;
- rien ne s'oppose ﺣ ce qu'un fragment soit ﺣ nouveau fragmentﺣ۸.
- Cette opﺣ۸ration est absolument transparente pour les couches de transport qui utilisent IP.
- Quand un datagramme est fragmentﺣ۸, chaque fragment comporte la mﺣ۹me valeur de champ IDENTIFICATION que le datagramme initial.
S'il y a encore des fragments, un des bits du champ FLAGS est positionnﺣ۸ ﺣ 1 pour indiquer ﺡ،ﺡ More fragmentﺡ ﺡﭨﺡ !
Ce champ a une longueur de trois bits.
FRAGMENT OFFSET contient l'offset du fragment, relativement au datagramme initial.
Cet offset est codﺣ۸ sur 13 bits.
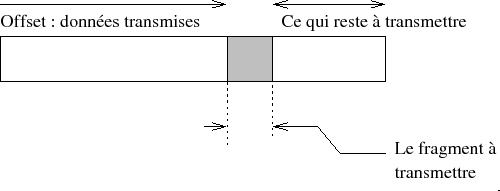
Pour tous les fragmentsﺡ :
- les donnﺣ۸es doivent faire un multiple de huit octets, sauf pour le dernier fragment, ﺣ۸videmmentﺡ ;
- le champ TOTAL LENGTH changeﺡ ;
- chaque fragment est un datagramme indﺣ۸pendant, susceptible d'ﺣ۹tre ﺣ son tour fragmentﺣ۸.
Pour le dernier fragmentﺡ :
- FLAGS est remis ﺣ zﺣ۸roﺡ ;
- les donnﺣ۸es ont une taille quelconque.
5-1-4-2. Rﺣ۸assemblage▲
- Tous les datagrammes issus d'une fragmentation deviennent des datagrammes IP comme (presque) les autres.
- Ils arrivent ﺣ destination, peuvent ﺣ۹tre dans le dﺣ۸sordre, dupliquﺣ۸s. IP doit faire le tri.
- Il y a suffisamment d'information dans l'entﺣ۹te pour rﺣ۸assembler les fragments ﺣ۸pars.
- Mais si un fragment manque, la totalitﺣ۸ du datagramme est perdu car aucun mﺣ۸canisme de contrﺣﺑle n'est implﺣ۸mentﺣ۸ pour cela dans IP.
C'est la raison principale pour laquelle il faut absolument ﺣ۸viter de fragmenter un datagramme IPﺡ !
La figure IV.05 rﺣ۸sume l'opﺣ۸ration de fragmentation d'un datagramme IP.
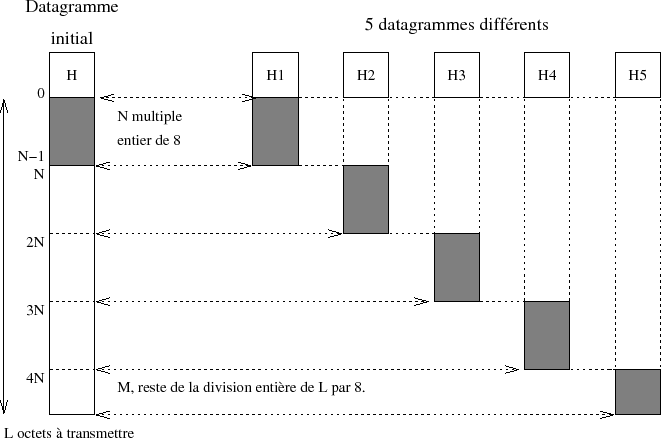
| ﺡ | H1 | H2 | H3 | H4 | H5 | ﺡ |
| IDENTIFICATION | I | I | I | I | I | ﺡ |
| FLAG | MF | MF | MF | MF | 0 | ﺡ |
| OFFSET | 0 | N | 2 x N | 3 x N | 4 x N | ﺡ |
| TOTAL LENGTH | H+N | H+N | H+N | H+N | H+M | ﺡ |
| HEADER CHECKSUM | C 1 | C 2 | C 3 | C 4 | C 5 | ﺡ |
Notez les variations de certains champs de l'entﺣ۹teﺡ :
- IDENTIFICATION est le mﺣ۹me pour tous.
- FLAG est 0 pour le dernier datagramme.
- OFFSET croﺣ؟t de la taille du fragment, ici N.
- TOTAL LENGTH est gﺣ۸nﺣ۸ralement diffﺣ۸rent pour le dernier fragment, sauf cas particulier.
- HEADER CHECKSUM change ﺣ chaque fois, car l'OFFSET change (rappelﺡ : il ne tient pas compte des donnﺣ۸es).
5-2. Protocole ARP▲
ARP est l'acronyme de ﺡ،ﺡ Address Resolution Protocolﺡ ﺡﭨ, il est dﺣ۸fini dans la RFC 826.
- Le problﺣ۷me ﺣ rﺣ۸soudre est issu de la constatation qu'une adresse IP n'a de sens que pour la suite de protocole TCP/IPﺡ ; celle-ci ﺣ۸tant indﺣ۸pendante de la partie matﺣ۸rielle il faut avoir un moyen d'ﺣ۸tablir un lien entre ces deux constituants.
- La norme Ethernet (vs IEEE) suppose l'identification unique de chaque carte construite et vendue(40).
- Sur une mﺣ۹me liaison physique (lire plus loin ﺡ،ﺡ mﺣ۹me LANﺡ ﺡﭨ), Ethernet par exemple, deux machines peuvent communiquer si elles connaissent leurs adresses physiques respectives.
On suppose qu'une machine connaﺣ؟t sa propre adresse physique par un moyen qui n'est pas dﺣ۸crit ici (ne fait pas partie du protocole).
Remarque importanteﺡ : cette information n'a pas de sens dans le cadre d'une liaison de type ﺡ،ﺡ point ﺣ pointﺡ ﺡﭨ avec un protocole tel que ppp.
- Lors du premier ﺣ۸change entre deux machines d'un mﺣ۹me LAN, si les adresses physiques ne sont pas dﺣ۸jﺣ connues (on verra pourquoi plus loin), la solution ﺣ ce problﺣ۷me passe par l'usage du protocole ARP.
- L'usage d'ARP est complﺣ۷tement transparent pour l'utilisateur.
5-2-1. Fonctionnement▲
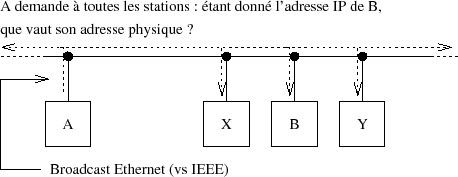
Sur la figure IV.06 la station Ethernet A (IA, PA) a besoin de connaﺣ؟tre l'adresse physique de la station Ethernet B (IB, PB). Pour ce faire, elle envoie un datagramme de format spﺣ۸cial (cf. paragraphe suivant), dﺣ۸diﺣ۸ ﺣ ARP, qui lui permet de poser la question (ﺡ،ﺡ Arp questionﺡ ﺡﭨ) ﺣ l'ensemble des machines actives. L'adresse de la machine qui doit rﺣ۸pondre ﺣ۸tant l'objet de la question, son adresse (champ destinataire) est donc remplacﺣ۸e par une adresse de ﺡ،ﺡ broadcastﺡ ﺡﭨ (48 bits ﺣ 1).
Toutes les machines du LAN ﺣ۸coutent cet ﺣ۸change et peuvent mettre ﺣ jour leur table de conversion (adresse IP - adresse Ethernet) pour la machine A.
Remarqueﺡ : quand une station Ethernet ne rﺣ۸pond plus (cf. ICMP) il y a suppression de l'association adresse IP - adresse MAC.
Le ﺡ،ﺡ broadcastﺡ ﺡﭨ, coﺣﭨteux en bande passante, est ainsi utilisﺣ۸ au maximum de ses possibilitﺣ۸s. Sur la figure V.07 la rﺣ۸ponse de B est du type ﺡ،ﺡ unicastﺡ ﺡﭨ.
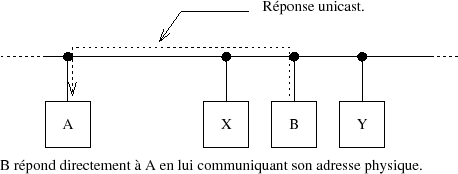
Si la station B ne rﺣ۸pond pas, la station continuera ﺣ poser la question ﺣ intervalles rﺣ۸guliers pendant un temps infini...
Il n'est pas besoin d'utiliser ARP prﺣ۸alablement ﺣ chaque ﺣ۸change, car heureusement le rﺣ۸sultat est mﺣ۸morisﺣ۸.
En rﺣ۷gle gﺣ۸nﺣ۸rale la durﺣ۸e de vie d'une adresse en mﺣ۸moire est de l'ordre de 20 minutes et chaque utilisation remet ﺣ jour ce compteur.
La commande arp -a sous Unix permet d'avoir le contenu de la table de la machine sur laquelle on se trouve, par exempleﺡ :
$ arp -a
soupirs.chezmoi.fr (192.168.192.10) at 8:0:9:85:76:9c
espoirs.chezmoi.fr (192.168.192.11) at 8:0:9:85:76:bd
plethore.chezmoi.fr (192.168.192.12) at 8:0:9:a:f9:aa
byzance.chezmoi.fr (192.168.192.13) at 8:0:9:a:f9:bc
ramidus.chezmoi.fr (192.168.192.14) at 0:4f:49:1:28:22 permanent
desiree.chezmoi.fr (192.168.192.33) at 8:0:9:70:44:52
pythie.chezmoi.fr (192.168.192.34) at 0:20:af:2f:8f:f1
ramidus.chezmoi.fr (192.168.192.35) at 0:4f:49:1:36:50 permanent
gateway.chezmoi.fr (192.168.192.36) at 0:60:8c:81:d5:1bEnfin, et c'est un point trﺣ۷s important, du fait de l'utilisation de ﺡ،ﺡ broadcastﺡ ﺡﭨ physique, les messages ARP ne franchissent pas les routeurs. Il existe cependant un cas particulierﺡ : le proxy ARP, que nous ﺣ۸voquerons succinctement ﺣ la fin de ce paragraphe.
5-2-2. Format du datagramme▲
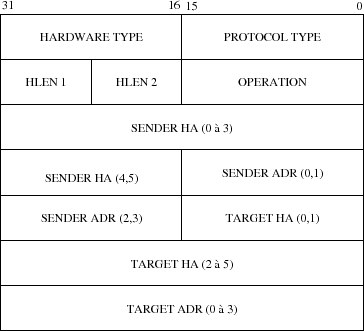
Le datagramme ci-dessus est encapsulﺣ۸ dans une trame physique du type 0x0806(41).
HARDWARE TYPEﺡ : pour spﺣ۸cifier le type d'adresse physique dans les champs SENDER HA et TARGET HA, c'est 1 pour Ethernet.
PROTOCOL TYPEﺡ : pour spﺣ۸cifier le type d'adresse logique dans les champs SENDER ADR et TARGET ADR, c'est 0x0800 (mﺣ۹me valeur que dans la trame Ethernet) pour des adresses IP.
HLEN 1ﺡ : pour spﺣ۸cifier la longueur de l'adresse physique (six octets pour Ethernet).
HLEN 2ﺡ : pour spﺣ۸cifier la longueur de l'adresse logique (quatre octets pour IP).
OPERATIONﺡ : ce champ prﺣ۸cise le type de l'opﺣ۸ration, il est nﺣ۸cessaire, car la trame est la mﺣ۹me pour toutes les opﺣ۸rations des deux protocoles qui l'utilisent.
| ﺡ | Question | Rﺣ۸ponse |
| ARP | 1 | 2 |
| RARP | 3 | 4 |
SENDER HAﺡ : adresse physique de l'ﺣ۸metteur.
SENDER ADRﺡ : adresse logique de l'ﺣ۸metteur.
TARGET HAﺡ : adresse physique du destinataire.
TARGET ADRﺡ : adresse logique du destinataire.
5-2-3. Proxy ARP▲
Le proxy ARP permet l'extension du LAN ﺣ des hﺣﺑtes qui ne lui sont pas directement physiquement reliﺣ۸s, mais qui s'y rattachent par exemple au travers d'une passerelle.
Un exemple trﺣ۷s courant est celui d'un hﺣﺑte qui accﺣ۷de ﺣ un rﺣ۸seau via un dialup (rtc, numﺣ۸ris...). Le NetID de son adresse IP peut alors ﺣ۹tre le mﺣ۹me que celui du rﺣ۸seau rejoint, comme s'il y ﺣ۸tait physiquement raccordﺣ۸. Ce subterfuge est rendu possible aprﺣ۷s configuration adﺣ۸quate de la passerelle de raccordement.
5-3. Protocole RARP▲
RARP est l'acronyme de ﺡ،ﺡ Reverse Address Resolution Protocolﺡ ﺡﭨ, il est dﺣ۸fini dans la RFC 903 (BOOTP et DHCP en sont des alternatives avec plus de possibilitﺣ۸s).
- Normalement une machine qui dﺣ۸marre obtient son adresse IP par lecture d'un fichier sur son disque dur (ou depuis sa configuration figﺣ۸e dans une mﺣ۸moire non volatile).
- Pour certains ﺣ۸quipements cette opﺣ۸ration n'est pas possible, voire non souhaitﺣ۸e par l'administrateur du rﺣ۸seauﺡ :
- terminaux X Windowsﺡ ;
- stations de travail ﺡ،ﺡ disklessﺡ ﺡﭨﺡ ;
- imprimante en rﺣ۸seauﺡ ;
- ﺡ،ﺡ boites noiresﺡ ﺡﭨ sans capacitﺣ۸ autonome de dﺣ۸marrageﺡ ;
- PC en rﺣ۸seauﺡ ;
- ...
- Pour communiquer en TCP/IP une machine a besoin d'au moins une adresse IP, l'idﺣ۸e de ce protocole est de la demander au rﺣ۸seau.
- Le protocole RARP est adaptﺣ۸ de ARPﺡ : l'ﺣ۸metteur envoie une requﺣ۹te RARP spﺣ۸cifiant son adresse physique dans un datagramme de mﺣ۹me format que celui de ARP et avec une adresse de ﺡ،ﺡ broadcastﺡ ﺡﭨ physique. Le champ OPERATION contient alors le code de ﺡ،ﺡ RARP questionﺡ ﺡﭨ.
- Toutes les stations en activitﺣ۸ reﺣ۶oivent la requﺣ۹te, celles qui sont habilitﺣ۸es ﺣ rﺣ۸pondre (serveurs RARP) complﺣ۷tent le datagramme et le renvoient directement (ﺡ،ﺡ unicastﺡ ﺡﭨ) ﺣ l'ﺣ۸metteur de la requﺣ۹te puisqu'elles connaissent son adresse physique.
Sur une machine Unix configurﺣ۸e en serveur RARP, les correspondances entres adresses IP et adresses physiques sont enregistrﺣ۸es dans un fichier nommﺣ۸ gﺣ۸nﺣ۸ralement /etc/bootptab.
5-4. Protocole ICMP▲
ICMP est l'acronyme de ﺡ،ﺡ Internet Control Message Protocolﺡ ﺡﭨ, il est historiquement dﺣ۸fini dans la RFC 950.
Nous avons vu que le protocole IP ne vﺣ۸rifie pas si les paquets ﺣ۸mis sont arrivﺣ۸s ﺣ leur destinataire dans de bonnes conditions.
Les paquets circulent d'une passerelle vers une autre jusqu'ﺣ en trouver une qui puisse les dﺣ۸livrer directement ﺣ un hﺣﺑte. Si une passerelle ne peut router ou dﺣ۸livrer directement un paquet ou si un ﺣ۸vﺣ۸nement anormal arrive sur le rﺣ۸seau comme un trafic trop important ou une machine indisponible, il faut pouvoir en informer l'hﺣﺑte qui a ﺣ۸mis le paquet. Celui-ci pourra alors rﺣ۸agir en fonction du type de problﺣ۷me rencontrﺣ۸.
ICMP est un mﺣ۸canisme de contrﺣﺑle des erreurs au niveau IP, mais la figure II.02 du chapitre d'introduction ﺣ IP montre que le niveau Application peut ﺣ۸galement avoir un accﺣ۷s direct ﺣ ce protocole.
5-4-1. Le systﺣ۷me de messages d'erreur▲
Dans le systﺣ۷me que nous avons dﺣ۸crit, chaque passerelle et chaque hﺣﺑte opﺣ۷re de maniﺣ۷re autonome, route et dﺣ۸livre les datagrammes qui arrivent sans coordination avec l'ﺣ۸metteur.
Le systﺣ۷me fonctionne parfaitement si toutes les machines sont en ordre de marche et si toutes les tables de routage sont ﺣ jour. Malheureusement c'est une situation idﺣ۸ale...
Il peut y avoir des ruptures de lignes de communication, des machines peuvent ﺣ۹tre ﺣ l'arrﺣ۹t, en pannes, dﺣ۸connectﺣ۸es du rﺣ۸seau ou incapables de router les paquets parce qu'en surcharge.
Des paquets IP peuvent alors ne pas ﺣ۹tre dﺣ۸livrﺣ۸s ﺣ leur destinataire et le protocole IP lui-mﺣ۹me ne contient rien qui puisse permettre de dﺣ۸tecter cet ﺣ۸chec de transmission.
C'est pourquoi est ajoutﺣ۸ systﺣ۸matiquement un mﺣ۸canisme de gestion des erreurs connu sous le doux nom de ICMP. Il fait partie de la couche IP(42) et porte le numﺣ۸ro de protocole 1.
Ainsi, quand un message d'erreur arrive pour un paquet ﺣ۸mis, c'est la couche IP elle-mﺣ۹me qui gﺣ۷re le problﺣ۷me, la plupart des cas sans en informer les couches supﺣ۸rieures (certaines applications utilisent ICMP(43)).
Initialement prﺣ۸vu pour permettre aux passerelles d'informer les hﺣﺑtes sur des erreurs de transmission, ICMP n'est pas restreint aux ﺣ۸changes passerelles-hﺣﺑtes, des ﺣ۸changes entre hﺣﺑtes sont tout ﺣ fait possibles.
Le mﺣ۹me mﺣ۸canisme est valable pour les deux types d'ﺣ۸changes.
5-4-2. Format des messages ICMP▲
Chaque message ICMP traverse le rﺣ۸seau dans la partie DATA d'un datagramme IPﺡ :

La consﺣ۸quence directe est que les messages ICMP sont routﺣ۸s comme les autres paquets IP ﺣ travers le rﺣ۸seau. Il y a toutefois une exceptionﺡ : il peut arriver qu'un paquet d'erreur rencontre lui-mﺣ۹me un problﺣ۷me de transmission, dans ce cas on ne gﺣ۸nﺣ۷re pas d'erreur sur l'erreurﺡ !
La figure IV.10 dﺣ۸crit le format du message ICMPﺡ :

Il est important de bien voir que puisque les messages ICMP sont encapsulﺣ۸s dans un datagramme IP, ICMP n'est pas considﺣ۸rﺣ۸ comme un protocole de niveau plus ﺣ۸levﺣ۸.
La raison de l'utilisation d'IP pour dﺣ۸livrer de telles informations est que les messages peuvent avoir ﺣ traverser plusieurs rﺣ۸seaux avant d'arriver ﺣ leur destination finale. Il n'ﺣ۸tait donc pas possible de rester au niveau physique du rﺣ۸seau (ﺣ l'inverse de ARP ou RARP).
Chaque message ICMP a un type particulier qui caractﺣ۸rise le problﺣ۷me qu'il signale. Un entﺣ۹te de 32 bits est composﺣ۸ comme suitﺡ :
TYPEﺡ : contient le code d'erreur.
CODEﺡ : complﺣ۷te l'information du champ prﺣ۸cﺣ۸dent.
CHECKSUMﺡ : est utilisﺣ۸ avec le mﺣ۹me mﺣ۸canisme de vﺣ۸rification que pour les datagrammes IP, mais ici il ne porte que sur le message ICMP (rappelﺡ : le checksum de l'entﺣ۹te IP ne porte que sur son entﺣ۹te et non sur les donnﺣ۸es vﺣ۸hiculﺣ۸es).
En addition, les messages ICMP donnent toujours l'entﺣ۹te IP et les 64 premiers bits (les deux premiers mots de quatre octets) du datagramme qui est ﺣ l'origine du problﺣ۷me, pour permettre au destinataire du message d'identifier quel paquet est ﺣ l'origine du problﺣ۷me.
5-4-3. Quelques types de messages ICMP▲
Ce paragraphe examine quelques-uns des principaux types de messages ICMP, ceux qui sont le plus utilisﺣ۸s. Il existe onze valeurs de TYPE diffﺣ۸rentes.
ﺡ،ﺡ Echo Request (8), Echo reply (0)ﺡ ﺡﭨ
- Une machine envoie un message ICMP ﺡ،ﺡ echo requestﺡ ﺡﭨ pour tester si son destinataire est accessible. N'importe quelle machine qui reﺣ۶oit une telle requﺣ۹te doit formuler un message ICMP ﺡ،ﺡ echo replyﺡ ﺡﭨ en retour(44).
- Ce mﺣ۸canisme est extrﺣ۹mement utile, la plupart des implﺣ۸mentations le proposent sous forme d'un utilitaire (ping sous Unix).
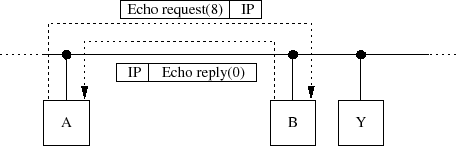
ﺡ،ﺡ Destination Unreachable (3)ﺡ ﺡﭨ
- Quand une passerelle ne peut pas dﺣ۸livrer un datagramme IP, elle envoie un message ICMP ﺡ،ﺡ destination unreachableﺡ ﺡﭨ ﺣ l'ﺣ۸metteur.
- Dans ce cas le champ CODE complﺣ۷te le message d'erreur avecﺡ :
- 0ﺡ : ﺡ،ﺡ Network unreachableﺡ ﺡﭨﺡ ;
- 1ﺡ : ﺡ،ﺡ Host unreachableﺡ ﺡﭨﺡ ;
- 2ﺡ : ﺡ،ﺡ Protocol unreachableﺡ ﺡﭨﺡ ;
- 3ﺡ : ﺡ،ﺡ Port unreachableﺡ ﺡﭨﺡ ;
- 4ﺡ : ﺡ،ﺡ Fragmentation needed and DF setﺡ ﺡﭨﺡ ;
- 5ﺡ : ﺡ،ﺡ Source route failedﺡ ﺡﭨ.
ﺡ،ﺡ Source Quench (4)ﺡ ﺡﭨ
- Quand un datagramme IP arrive trop vite pour une passerelle ou un hﺣﺑte, il est rejetﺣ۸.
- Un paquet arrive ﺡ،ﺡ trop viteﺡ ﺡﭨ quand la machine qui doit le lire est congestionnﺣ۸e, trop de trafic ﺣ suivre...
- Dans ce cas la machine en question envoie un paquet ICMP ﺡ،ﺡ source quenchﺡ ﺡﭨ qui est interprﺣ۸tﺣ۸ de la faﺣ۶on suivanteﺡ :
- l'ﺣ۸metteur ralenti le rythme d'envoi de ses paquets jusqu'ﺣ ce qu'il cesse de recevoir ce message d'erreur. La vitesse est donc ajustﺣ۸e par une sorte d'apprentissage rustique. Puis graduellement il augmente le dﺣ۸bit, aussi longtemps que le message ﺡ،ﺡ source quenchﺡ ﺡﭨ ne revient pas.
- Ce type de paquet ICMP a donc tendance ﺣ vouloir rﺣ۸guler le flux des datagrammes au niveau IP alors que c'est une fonctionnalitﺣ۸ de la couche de transport (TCP).
- C'est donc une sﺣ۸rieuse entorse ﺣ la rﺣ۷gle d'indﺣ۸pendance des couches.
ﺡ،ﺡ Redirect (5)ﺡ ﺡﭨ
- Les tables de routage (voir le paragraphe 6) des stations restent assez statiques durant de longues pﺣ۸riodes. Le systﺣ۷me d'exploitation les lit au dﺣ۸marrage sur le systﺣ۷me de fichiers et l'administrateur en change de temps en temps les ﺣ۸lﺣ۸ments.
- Si entre deux modifications une destination change d'emplacement, la donnﺣ۸e initiale dans la table de routage peut s'avﺣ۸rer incorrecte.
- Les passerelles connaissent de bien meilleures routes que les hﺣﺑtes eux-mﺣ۹mes, ainsi quand une passerelle dﺣ۸tecte une erreur de routage, elle fait deux chosesﺡ :
- elle envoie ﺣ l'ﺣ۸metteur du paquet un message ICMP ﺡ،ﺡ redirectﺡ ﺡﭨﺡ ;
- elle redirige le paquet vers la bonne destination.
- Cette redirection ne rﺣ۷gle pas les problﺣ۷mes de routage, car elle est limitﺣ۸e aux interactions entre passerelles et hﺣﺑtes directement connectﺣ۸s.
- La propagation des routes au travers des rﺣ۸seaux multiples est un autre problﺣ۷me.
- Le champ CODE du message ICMP peut avoir les valeurs suivantesﺡ :
- 0ﺡ : ﺡ،ﺡ Redirect datagram for the Netﺡ ﺡﭨﺡ ;
- 1ﺡ : ﺡ،ﺡ Redirect datagram for the hostﺡ ﺡﭨﺡ ;
- 2ﺡ : ...
ﺡ،ﺡ Router solicitation (10) vs Router advertisement (9)ﺡ ﺡﭨ
- Il s'agit d'obtenir ou d'annoncer des routes, nous verrons cela plus en dﺣ۸tail dans le paragraphe 6.4.
ﺡ،ﺡ Time exceeded (11)ﺡ ﺡﭨ
- Chaque datagramme contient un champ TTL dit ﺡ،ﺡ TIME TO LIVEﺡ ﺡﭨ appelﺣ۸ aussi ﺡ،ﺡ hop countﺡ ﺡﭨ.
- Afin de prﺣ۸venir le cas oﺣﺗ un paquet circulerait ﺣ l'infini d'une passerelle ﺣ une autre, chaque passerelle dﺣ۸crﺣ۸mente ce compteur, rejette le paquet quand le compteur arrive ﺣ zﺣ۸ro et envoie un message ICMP ﺣ l'ﺣ۸metteur pour le tenir au courant.
5-5. Protocole IGMP▲
IGMP, l'acronyme de ﺡ،ﺡ Internet Group Management Protocolﺡ ﺡﭨ, est historiquement dﺣ۸fini dans l'Annexe I de la RFC 1112.
Sa raison d'ﺣ۹tre est que les datagrammes ayant une adresse multicast sont ﺣ destination d'un groupe d'utilisateurs dont l'ﺣ۸metteur ne connaﺣ؟t ni le nombre ni l'emplacement. L'usage du multicast ﺣ۸tant par construction dﺣ۸diﺣ۸ aux applications comme la radio ou la vidﺣ۸o sur le rﺣ۸seau(45), donc consommatrices de bande passante, il est primordial que les routeurs aient un moyen de savoir s'il y a des utilisateurs de tel ou tel groupe sur les LAN directement accessibles pour ne pas encombrer les bandes passantes associﺣ۸es avec des flux d'octets que personne n'utilise plusﺡ !
5-5-1. Description de l'entﺣ۹te▲

IGMP est un protocole de communication entre les routeurs susceptibles de transmettre des datagrammes multicast et des hﺣﺑtes qui veulent s'enregistrer dans tel ou tel groupe. IGMP est encapsulﺣ۸ dans IP(46) avec le protocole numﺣ۸ro 2. Comme le montre la figure IV.12, sa taille est fixe (contrairement ﺣ ICMP)ﺡ : seulement deux mots de quatre octets.
- Versionﺡ : version 1.
- Typeﺡ : ce champ prend deux valeurs, 1 pour dire qu'il s'agit d'une question (query d'un routeur), 2 pour dire qu'il s'agit de la rﺣ۸ponse d'un hﺣﺑte.
- Inutilisﺣ۸ﺡ : ...
- Checksumﺡ : le checksum est calculﺣ۸ comme celui d'ICMP.
- Adresseﺡ : c'est l'adresse multicast (classe D) ﺣ laquelle appartient l'hﺣﺑte qui rﺣ۸pond.
5-5-2. Fonctionnement du protocole▲
La RFC 1112 prﺣ۸cise que les routeurs multicast envoient des messages de questionnement (Type=Queries) pour reconnaﺣ؟tre quels sont les ﺣ۸ventuels hﺣﺑtes appartenant ﺣ quel groupe. Ces questions sont envoyﺣ۸es ﺣ tous les hﺣﺑtes des LAN directement raccordﺣ۸s ﺣ l'aide de l'adresse multicast du groupe 224.0.0.1(47) encapsulﺣ۸ dans un datagramme IP ayant un champ TTL=1. Tous les hﺣﺑtes susceptibles de joindre un groupe multicast ﺣ۸coutent ce groupe par hypothﺣ۷se.
Les hﺣﺑtes, dont les interfaces ont ﺣ۸tﺣ۸ correctement configurﺣ۸es, rﺣ۸pondent ﺣ une question par autant de rﺣ۸ponses que de groupes auxquels ils appartiennent sur l'interface rﺣ۸seau qui a reﺣ۶u la question. Afin d'ﺣ۸viter une ﺡ،ﺡ tempﺣ۹te de rﺣ۸ponsesﺡ ﺡﭨ, chaque hﺣﺑte met en ﺧuvre la stratﺣ۸gie suivanteﺡ :
- Un hﺣﺑte ne rﺣ۸pond pas immﺣ۸diatement ﺣ la question reﺣ۶ue. Pour chaque groupe auquel il appartient, il attend un dﺣ۸lai compris entre 0 et 10 secondes, calculﺣ۸ alﺣ۸atoirement ﺣ partir de l'adresse IP unicast de l'interface qui a reﺣ۶u la question, avant de renvoyer sa rﺣ۸ponse. La figure
IV.13 montre un tel ﺣ۸change, remarquez au passage la valeur des adresses. - La rﺣ۸ponse envoyﺣ۸e est ﺣ۸coutﺣ۸e par tous les membres du groupe appartenant au mﺣ۹me LAN. Tous ceux qui s'apprﺣ۹taient ﺣ envoyer une telle rﺣ۸ponse au serveur en interrompent le processus pour ﺣ۸viter une redite. Le routeur ne reﺣ۶oit ainsi qu'une seule rﺣ۸ponse pour chaque groupe, et pour chaque LAN, ce qui lui suffit pour justifier le routage demandﺣ۸.

Il y a deux exceptions ﺣ la stratﺣ۸gie ci-dessus. La premiﺣ۷re est que si une question est reﺣ۶ue alors que le compte ﺣ rebours pour rﺣ۸pondre ﺣ une rﺣ۸ponse est en cours, il n'est pas interrompu.
La deuxiﺣ۷me est qu'il n'y a jamais de dﺣ۸lai appliquﺣ۸ pour l'envoi de datagramme portant l'adresse du groupe de base 224.0.0.1.
Pour rafraﺣ؟chir leur connaissance des besoins de routage, les routeurs envoient leurs questions avec une frﺣ۸quence trﺣ۷s faible de l'ordre de la minute, afin de prﺣ۸server au maximum la bande passante du rﺣ۸seau. Si aucune rﺣ۸ponse ne leur parvient pour tel ou tel groupe demandﺣ۸ prﺣ۸cﺣ۸demment, le routage s'interrompt.
Quand un hﺣﺑte rejoint un groupe, il envoie immﺣ۸diatement une rﺣ۸ponse (type=report) pour le groupe (les) qui l'intﺣ۸resse, plutﺣﺑt que d'attendre une question du routeur. Au cas oﺣﺗ cette rﺣ۸ponse se perdrait, il est recommandﺣ۸ d'effectuer une rﺣ۸ﺣ۸mission dans un court dﺣ۸lai.
Remarquesﺡ :
- Sur un LAN sans routeur pour le multicast, le seul trafic IGMP est celui des hﺣﺑtes demandant ﺣ rejoindre tel ou tel groupe.
- Il n'y a pas de report pour quitter un groupe.
- La plage d'adresses multicast entre 224.0.0.0 et 224.0.0.225 est dﺣ۸diﺣ۸e aux applications utilisant une valeur de 1 pour le champ TTL (administration et services au niveau du LAN). Les routeurs ne doivent pas transmettre de tels datagrammes.
- Il n'y a pas de message ICMP sur les datagrammes ayant une adresse de destination du type multicast.
En consﺣ۸quence les applications qui utilisent le multicast (avec une adresse supﺣ۸rieure ﺣ 224.0.0.225) pour dﺣ۸couvrir des services, doivent avoir une stratﺣ۸gie pour augmenter la valeur du champ TTL en cas de non-rﺣ۸ponse.
5-5-3. Fonctionnement du Mbone▲
Prﺣ۸cisions en cours...
5-6. Routage IP▲
Ce paragraphe dﺣ۸crit de maniﺣ۷re succincte le routage des datagrammes. Sur l'Internet, ou au sein de toute entitﺣ۸ qui utilise IP, les datagrammes ne sont pas routﺣ۸s par des machines Unix, mais par des routeurs dont c'est la fonction par dﺣ۸finition. Ils sont plus efficaces et plus perfectionnﺣ۸s pour cette tﺣ۱che par construction, et surtout autorisent l'application d'une politique de routage (ﺡ،ﺡ routing policyﺡ ﺡﭨ) ce que la pile IP standard d'une machine Unix ne sait pas faire. Toutefois il est courant dans les ﺡ،ﺡ petits rﺣ۸seauxﺡ ﺡﭨ, ou quand le problﺣ۷me ﺣ rﺣ۸soudre reste simple, de faire appel ﺣ une machine Unix pour ce faire(48).
Dans ce paragraphe nous examinons le problﺣ۷me du routage de maniﺣ۷re synthﺣ۸tique, nous aborderons plus en dﺣ۸tail les aspects techniques du routage dynamique au chapitre 7.
Le routage des datagrammes se fait au niveau de la couche IP, et c'est son travail le plus important. Toutes les machines multiprocessus sont thﺣ۸oriquement capables d'effectuer cette opﺣ۸ration.
La diffﺣ۸rence entre un ﺡ،ﺡ routeurﺡ ﺡﭨ et un ﺡ،ﺡ hﺣﺑteﺡ ﺡﭨ est que le premier est capable de transmettre un datagramme d'une interface ﺣ une autre et pas le deuxiﺣ۷me.
Cette opﺣ۸ration est dﺣ۸licate si les machines qui doivent dialoguer sont connectﺣ۸es ﺣ de multiples rﺣ۸seaux physiques.
D'un point de vue idﺣ۸al, ﺣ۸tablir une route pour des datagrammes devrait tenir compte d'ﺣ۸lﺣ۸ments comme la charge du rﺣ۸seau, la taille des datagrammes, le type de service demandﺣ۸, les dﺣ۸lais de propagation, l'ﺣ۸tat des liaisons, le trajet le plus court... La pratique est plus rudimentaireﺡ !
Il s'agit de transporter des datagrammes au travers de multiples rﺣ۸seaux physiques, donc au travers de multiples passerelles.
On divise le routage en deux grandes famillesﺡ :
Le routage direct
- Il s'agit de dﺣ۸livrer un datagramme ﺣ une machine raccordﺣ۸e au mﺣ۹me LAN.
- L'ﺣ۸metteur trouve l'adresse physique du correspondant (ARP), encapsule le datagramme dans une trame et l'envoie.
Le routage indirect
- Le destinataire n'est pas sur le mﺣ۹me LAN comme prﺣ۸cﺣ۸demment. Il est absolument nﺣ۸cessaire de franchir une passerelle connue d'avance ou d'employer un chemin par dﺣ۸faut.
- En effet, toutes les machines ﺣ atteindre ne sont pas forcﺣ۸ment sur le mﺣ۹me rﺣ۸seau physique. C'est le cas le plus courant, par exemple sur l'Internet qui regroupe des centaines de milliers de rﺣ۸seaux diffﺣ۸rents.
- Cette opﺣ۸ration est beaucoup plus dﺣ۸licate que la prﺣ۸cﺣ۸dente, car il faut sﺣ۸lectionner une passerelle.
Parce que le routage est une opﺣ۸ration fondamentalement orientﺣ۸e ﺡ،ﺡ rﺣ۸seauﺡ ﺡﭨ, le routage s'appuie sur cette partie de l'adresse IP du destinataire. La couche IP dﺣ۸termine celle-ci en examinant les bits de poids fort qui conditionnent la classe d'adresse et donc la segmentation ﺡ،ﺡ network.hostﺡ ﺡﭨ. Dans certains cas (CIDR) le masque de sous-rﺣ۸seau est aussi employﺣ۸.
Munie de ce numﺣ۸ro de rﺣ۸seau, la couche IP examine les informations contenues dans sa table de routage.
5-6-1. Table de routage▲
Sous Unix toutes les opﺣ۸rations de routage se font grﺣ۱ce ﺣ une table, dite ﺡ،ﺡ table de routageﺡ ﺡﭨ, qui se trouve dans le noyau lui-mﺣ۹me. La figure V.14 rﺣ۸sume la situationﺡ :
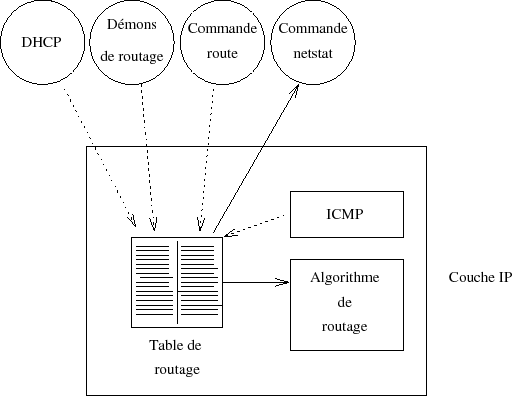
Cette table est trﺣ۷s frﺣ۸quemment utilisﺣ۸e par IP sur un serveur, plusieurs centaines de fois par secondes.
Comment est-elle crﺣ۸ﺣ۸eﺡ ?
Au dﺣ۸marrage avec la commande ﺡ،ﺡ routeﺡ ﺡﭨ, invoquﺣ۸e dans les scripts de lancement du systﺣ۷me, et en fonctionnementﺡ :
- au coup par coup avec la commande ﺡ،ﺡ routeﺡ ﺡﭨ, ﺣ partir du shell (administrateur systﺣ۷me uniquement)ﺡ ;
- dynamiquement avec les dﺣ۸mons de routage ﺡ،ﺡ routedﺡ ﺡﭨ ou ﺡ،ﺡ gatedﺡ ﺡﭨ (la frﺣ۸quence de mise ﺣ jour est typiquement de l'ordre de 30 s)ﺡ ;
- par des messages ﺡ،ﺡ ICMP redirectﺡ ﺡﭨ.
La commande netstat -rn permet de la visualiser au niveau de l'interface utilisateur (ﺡ،ﺡ Application layerﺡ ﺡﭨ)ﺡ :
$ netstat -rn
Routing tables
Internet:
Destination Gateway Flags
default 192.168.192.36 UGS
127.0.0.1 127.0.0.1 UH
192.168.192/27 link#1 UC
192.168.192.10 8:0:9:85:76:9c UHLW
192.168.192.11 8:0:9:85:76:bd UHLW
192.168.192.12 8:0:9:88:8e:31 UHLW
192.168.192.13 8:0:9:a:f9:bc UHLW
192.168.192.14 0:4f:49:1:28:22 UHLW
192.168.192.15 link#1 UHLW
192.168.192.32/27 link#2 UC
192.168.192.33 8:0:9:70:44:52 UHLW
192.168.192.34 0:20:af:2f:8f:f1 UHLW
192.168.192.35 0:4f:49:1:36:50 UHLW
192.168.192.36 link#2 UHLWOn peut mﺣ۸moriser cette table comme ﺣ۸tant essentiellement composﺣ۸e d'une colonne origine, d'une colonne destination.
De plus, chaque route qui dﺣ۸signe une passerelle (ici la route par dﺣ۸faut) doit s'accompagner d'un nombre de sauts (ﺡ،ﺡ hopﺡ ﺡﭨ), ou encore mﺣ۸trique, qui permet le choix d'une route plutﺣﺑt qu'une autre en fonction de cette valeur. Chaque franchissement d'un routeur compte pour un saut. Dans la table ci-dessus, la mﺣ۸trique de la route par dﺣ۸faut est 1.
Remarqueﺡ : la sortie de la commande netstat -rn ci-dessus a ﺣ۸tﺣ۸ simplifiﺣ۸e(49).
Les drapeaux (ﺡ،ﺡ flagsﺡ ﺡﭨ) les plus courantsﺡ :
| C | La route est gﺣ۸nﺣ۸rﺣ۸e par la machine, ﺣ l'usage. |
| D | La route a ﺣ۸tﺣ۸ crﺣ۸ﺣ۸e dynamiquement (dﺣ۸mons de routage). |
| G | La route dﺣ۸signe une passerelle, sinon c'est une route directe. |
| H | La route est vers une machine, sinon elle est vers un rﺣ۸seau. |
| L | Dﺣ۸signe la conversion vers une adresse physique (cf. ARP). |
| M | La route a ﺣ۸tﺣ۸ modifiﺣ۸e par un ﺡ،ﺡ redirectﺡ ﺡﭨ. |
| S | La route a ﺣ۸tﺣ۸ ajoutﺣ۸e manuellement. |
| U | La route est active. |
| W | La route est le rﺣ۸sultat d'un clonage. |
La figure IV.15 prﺣ۸cise l'architecture du rﺣ۸seau autour de la machine sur laquelle a ﺣ۸tﺣ۸ exﺣ۸cutﺣ۸ le netstat.
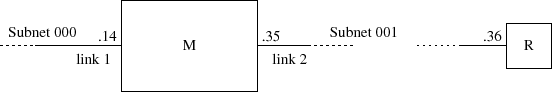
5-6-2. Routage statique▲
Comme nous avons pu le deviner au paragraphe prﺣ۸cﺣ۸dent, les routes statiques sont celles crﺣ۸ﺣ۸es au dﺣ۸marrage de la machine ou ajoutﺣ۸es manuellement par l'administrateur systﺣ۷me, en cours de fonctionnement.
Le nombre de machines possibles ﺣ atteindre potentiellement sur l'Internet est beaucoup trop ﺣ۸levﺣ۸ pour que chaque machine puisse espﺣ۸rer en conserver l'adresse, qui plus est, mﺣ۹me si cela ﺣ۸tait concevable, cette information ne serait jamais ﺣ jour donc inutilisable.
Plutﺣﺑt que d'envisager la situation prﺣ۸cﺣ۸dente, on prﺣ۸fﺣ۷re restreindre l'ﺣ۸tendue du ﺡ،ﺡ monde connuﺡ ﺡﭨ et utiliser la ﺡ،ﺡ stratﺣ۸gie de proche en procheﺡ ﺡﭨ prﺣ۸cﺣ۸demment citﺣ۸e.
Si une machine ne peut pas router un datagramme, elle connaﺣ؟t (ou est supposﺣ۸e connaﺣ؟tre) l'adresse d'une passerelle supposﺣ۸e ﺣ۹tre mieux informﺣ۸e pour transmettre ce datagramme.
Dans l'exemple de sortie de la commande netstat du paragraphe 6.1, on peut reconnaﺣ؟tre que l'administrateur systﺣ۷me n'a configurﺣ۸ qu'une seule route ﺡ،ﺡ manuellementﺡ ﺡﭨ(50), toutes les autres lignes ont ﺣ۸tﺣ۸ dﺣ۸duites par la couche IP elle-mﺣ۹me.
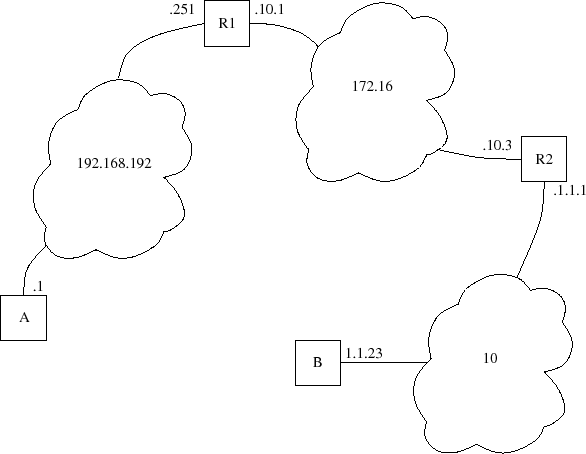
La figure V.16 met en situation plusieurs rﺣ۸seaux et les passerelles qui les relient. Voici une version trﺣ۷s simplifiﺣ۸e des tables de routage statiques oﺣﺗ sont prﺣ۸sentes les machines A, B, R1 et R2ﺡ :
Machine Aﺡ : defaultﺡ : 192.168.192.251
Machine Bﺡ : defaultﺡ : 10.1.1.1
Routeur R1ﺡ : 10ﺡ : 172.16.10.3
Routeur R2ﺡ : 192.168.192ﺡ : 172.16.10.1
5-6-2-1. Algorithme de routage▲
Cet algorithme simplifiﺣ۸ rﺣ۸sume les opﺣ۸rations de la couche IP pour choisir une destination, en fonction de sa table de routage. Cette opﺣ۸ration est essentiellement basﺣ۸e sur le numﺣ۸ro de rﺣ۸seau, IN, extrait de l'adresse IP, ID. M dﺣ۸signe la machine sur laquelle s'effectue le routage.
Si INﺡ : est un numﺣ۸ro de rﺣ۸seau auquel M est directement reliﺣ۸eﺡ :
- obtenir l'adresse physique de la machine destinatriceﺡ ;
- encapsuler le datagramme dans une trame physique et l'envoyer directement.
Sinon Si ID apparaﺣ؟t comme une machine ﺣ laquelle une route spﺣ۸ciale est attribuﺣ۸eﺡ :
- router le datagramme en fonction.
Sinon Si IN apparaﺣ؟t dans la table de routageﺡ :
- router le datagramme en fonction.
Sinon s'il existe une route par dﺣ۸fautﺡ :
- router le datagramme vers la passerelle ainsi dﺣ۸signﺣ۸e.
Sinonﺡ :
- dﺣ۸clarer une erreur de routage (ICMP).
5-6-3. Routage dynamique▲
Si la topologie d'un rﺣ۸seau offre la possibilitﺣ۸ de plusieurs routes pour atteindre une mﺣ۹me destination, s'il est vaste et complexe, sujet ﺣ des changements frﺣ۸quents de configuration... Le routage dynamique est alors un bon moyen d'entretenir les tables de routage et de maniﺣ۷re automatique.
Il existe de nombreux protocoles de routage dynamique dont certains sont aussi anciens que l'Internet. Nﺣ۸anmoins tous ne conviennent pas ﺣ tous les types de problﺣ۷me, il en existe une hiﺣ۸rarchie.
Schﺣ۸matiquement on peut imaginer l'Internet comme une hiﺣ۸rarchie de routeurs. Les routeurs principaux (ﺡ،ﺡ core gatewaysﺡ ﺡﭨ) de cette architecture utilisent entre eux des protocoles comme GGP (ﺡ،ﺡ Gateway to Gateway Protocolﺡ ﺡﭨ), l'ensemble de ces routeurs forment ce que l'on nomme l'ﺡ،ﺡ Internet Coreﺡ ﺡﭨ.
En bordure de ces routeurs principaux se situent les routeurs qui marquent la frontiﺣ۷re avec ce que l'on nomme les ﺡ،ﺡ Autonomous systemsﺡ ﺡﭨ, c'est-ﺣ -dire des systﺣ۷mes de routeurs et de rﺣ۸seaux qui possﺣ۷dent leurs mﺣ۸canismes propres de propagation des routes. Le protocole utilisﺣ۸ par ces routeurs limitrophes est souvent EGP (ﺡ،ﺡ Exterior Gateway Protocolﺡ ﺡﭨ) ou BGP (ﺡ،ﺡ Border Gateway Protocolﺡ ﺡﭨ).
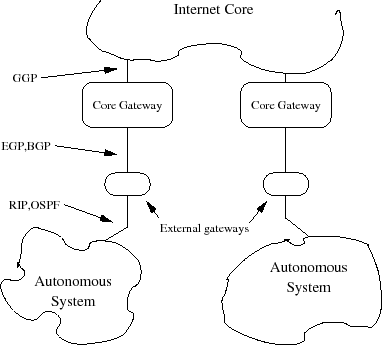
Au sein d'un systﺣ۷me autonome on utilise un IGP (ﺡ،ﺡ Interior Gateway Protocolﺡ ﺡﭨ), c'est-ﺣ -dire un ﺡ،ﺡ protocole de gateways intﺣ۸rieursﺡ ﺡﭨ. Les protocoles les plus couramment employﺣ۸s sont RIP (ﺡ،ﺡ Routing Information Protocolﺡ ﺡﭨ) qui est simple ﺣ comprendre et ﺣ utiliser, ou encore OSPF (ﺡ،ﺡ Open Shortest Path Firstﺡ ﺡﭨ) plus rﺣ۸cent, plus capable, mais aussi beaucoup plus complexe ﺣ comprendre dans son mode de fonctionnement, ou encore IS-IS de la couche ISO de l'OSI.
5-6-3-1. RIP - ﺡ،ﺡ Routing Information Protocolﺡ ﺡﭨ▲
RIP est apparu avec la version BSD d'Unix, il est documentﺣ۸ dans la RFC 1058 (1988 - Version 1 du protocole) et la RFC 1388 (1993 - Version 2 du protocole). Ce protocole est basﺣ۸ sur des travaux plus anciens menﺣ۸s par la firme Xerox.
RIP utilise le concept de ﺡ،ﺡ vecteur de distancesﺡ ﺡﭨ, qui s'appuie sur un algorithme de calcul du chemin le plus court dans un graphe. Le graphe est celui des routeurs, la longueur du chemin est ﺣ۸tablie en nombre de sauts (ﺡ،ﺡ hopﺡ ﺡﭨ), ou mﺣ۸trique, entre la source et la destination, c'est-ﺣ -dire en comptant toutes les liaisons. Cette distance est exprimﺣ۸e comme un nombre entier variant entre 1 et 15ﺡ ; la valeur 16 est considﺣ۸rﺣ۸e comme l'infini et indique une mise ﺣ l'ﺣ۸cart de la route.
Chaque routeur ﺣ۸met dans un datagramme portant une adresse IP de broadcast, ﺣ frﺣ۸quence fixe (environ 30 secondes), le contenu de sa table de routage et ﺣ۸coute celle des autres routeurs pour complﺣ۸ter sa propre table. Ainsi se propagent les tables de routes d'un bout ﺣ l'autre du rﺣ۸seau. Pour ﺣ۸viter une ﺡ،ﺡ tempﺣ۹te de mises ﺣ jourﺡ ﺡﭨ, le dﺣ۸lai de 30 secondes est augmentﺣ۸ d'une valeur alﺣ۸atoire comprise entre 1 et 5 secondes.
Si une route n'est pas annoncﺣ۸e au moins une fois en trois minutes, la distance devient ﺡ،ﺡ infinieﺡ ﺡﭨ, et la route sera retirﺣ۸e un peu plus tard de la table (elle est propagﺣ۸e avec cette mﺣ۸trique).
L'adresse IP utilisﺣ۸e est une adresse de multipoint (ﺡ،ﺡ multicastﺡ ﺡﭨ) comme nous verrons au paragraphe 6.4
Depuis la dﺣ۸finition de RIPv2 les routes peuvent ﺣ۹tre accompagnﺣ۸es du masque de sous-rﺣ۸seau qui les caractﺣ۸rise. Ainsi on peut avoir la situation suivanteﺡ :
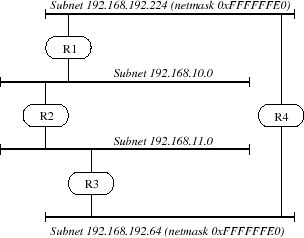
Aprﺣ۷s propagation des routes, la table de routage du routeur R1 pourrait bien ressembler ﺣ ﺡ :
| Source | Destination | Coﺣﭨt |
| 192.168.192.224 | R1 | 1 |
| 192.168.10.0 | R1 | 1 |
| 192.168.11.0 | R2 | 2 |
| 192.168.192.64 | R3 | 3 |
Avec une route par dﺣ۸faut qui est le routeur R2. La constitution de cette table n'est possible qu'avec RIPv2 ﺣ۸tant donnﺣ۸ l'existence des deux sous-rﺣ۸seaux de la classe C 192.168.192.
Le fonctionnement de ce protocole est dﺣ۸taillﺣ۸ plus loin.
5-6-3-2. OSPF - ﺡ،ﺡ Open Shortest Path Firstﺡ ﺡﭨ▲
Contrairement ﺣ RIP, OSPF n'utilise pas de vecteur de distances, mais base ses dﺣ۸cisions de routage sur le concept d'ﺡ،ﺡ ﺣ۸tats des liaisonsﺡ ﺡﭨ. Celui-ci permet un usage beaucoup plus fin des performances rﺣ۸elles des rﺣ۸seaux traversﺣ۸s, parce que cette mﺣ۸trique est changeante au cours du temps. Si on ajoute ﺣ cela une mﺣ۸thode de propagation trﺣ۷s rapide des routes par inondation, sans boucle et la possibilitﺣ۸ de chemins multiples, OSPF, bien que beaucoup plus complexe que RIP, a toutes les qualitﺣ۸s pour le remplacer, mﺣ۹me sur les tout petits rﺣ۸seaux.
OSPF doit son nom ﺣ l'algorithme d'Edsger W. Dijkstra(51) de recherche du chemin le plus court lors du parcours d'un graphe. Le ﺡ،ﺡ Openﺡ ﺡﭨ vient du fait qu'il s'agit d'un protocole ouvert de l'IETF, dans la RFC 2328...
Le fonctionnement de ce protocole est dﺣ۸taillﺣ۸ plus loin.
5-6-4. Dﺣ۸couverte de routeur et propagation de routes▲
Au dﺣ۸marrage d'une station, plutﺣﺑt que de configurer manuellement les routes statiques, surtout si elles sont susceptibles de changer et que le nombre de stations est grand, il peut ﺣ۹tre intﺣ۸ressant de faire de la ﺡ،ﺡ dﺣ۸couverte automatique de routeursﺡ ﺡﭨ (RFC 1256).
ﺣ intervalles rﺣ۸guliers les routeurs diffusent des messages ICMP de type 9 (ﺡ،ﺡ router advertisementﺡ ﺡﭨ) d'annonces de routes. Ces messages ont l'adresse multicast 224.0.0.1, qui est ﺣ destination de tous les hﺣﺑtes du LAN.
Toutes les stations capables de comprendre le multicast (et convenablement configurﺣ۸es pour ce faire) ﺣ۸coutent ces messages et mettent ﺣ jour leur table.
Les stations qui dﺣ۸marrent peuvent solliciter les routeurs si l'attente est trop longue (environ sept minutes) avec un autre message ICMP, de type 10 (ﺡ،ﺡ router sollicitationﺡ ﺡﭨ) et avec l'adresse multicast 224.0.0.2 (ﺣ destination de tous les routeurs de ce LAN). La rﺣ۸ponse du ou des routeurs est du type ﺡ،ﺡ unicastﺡ ﺡﭨ, sauf si le routeur s'apprﺣ۹tait ﺣ ﺣ۸mettre une annonce.
ﺣ chaque route est associﺣ۸ un niveau de prﺣ۸fﺣ۸rence et une durﺣ۸e de validitﺣ۸, dﺣ۸finis par l'administrateur du rﺣ۸seau. Une validitﺣ۸ nulle indique un routeur qui s'arrﺣ۹te et donc une route qui doit ﺣ۹tre supprimﺣ۸e.
Si entre deux annonces une route change, le mﺣ۸canisme de ﺡ،ﺡ ICMP redirectﺡ ﺡﭨ, examinﺣ۸ au paragraphe suivant, corrige l'erreur de route.
La dﺣ۸couverte de routeur n'est pas un protocole de routage, son objectif est bien moins ambitieuxﺡ : obtenir une route par dﺣ۸faut.
Il est intﺣ۸ressant de noter que sur les machines FreeBSD, c'est le dﺣ۸mon de routage routed qui effectue ce travail ﺣ la demande(52).
5-6-5. Message ICMP ﺡ،ﺡ redirectﺡ ﺡﭨ▲
La table de routage peut ﺣ۹tre modifiﺣ۸e dynamiquement par un message ICMP (IV).
La situation est celle de la figure IV.21.
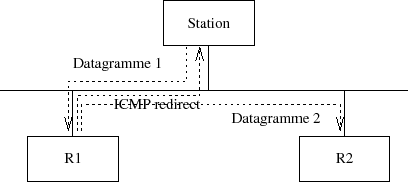
- La station veut envoyer un datagramme et sa table de routage lui commande d'utiliser la route qui passe par le routeur R1.
- Le routeur R1 reﺣ۶oit le datagramme, scrute sa table de routage et s'aperﺣ۶oit qu'il faut dﺣ۸sormais passer par R2. Pour ce faireﺡ :
- il reroute le datagramme vers R2, ce qui ﺣ۸vite qu'il soit ﺣ۸mis deux fois sur le LANﺡ ;
- il envoie un message ﺡ،ﺡ ICMP redirectﺡ ﺡﭨ (type 5) ﺣ la station, lui indiquant la nouvelle route vers R2ﺡ ;
- il reroute le datagramme vers R2, ce qui ﺣ۸vite qu'il soit ﺣ۸mis deux fois sur le LANﺡ ;
- il envoie un message ﺡ،ﺡ ICMP redirectﺡ ﺡﭨ (type 5) ﺣ la station, lui indiquant la nouvelle route vers R2.
Ce travail s'effectue pour chaque datagramme reﺣ۶u de la station.
- Dﺣ۷s que la station reﺣ۶oit le message ﺡ،ﺡ ICMP redirectﺡ ﺡﭨ elle met ﺣ jour sa table de routage. La nouvelle route est employﺣ۸e pour les datagrammes qui suivent (vers la mﺣ۹me direction).
La route modifiﺣ۸e est visible avec la commande netstat -r, elle figure avec le drapeau 'M' (modification dynamique).
Pour des raisons ﺣ۸videntes de sﺣ۸curitﺣ۸, cette possibilitﺣ۸ n'est valable que sur un mﺣ۹me LAN.
5-6-6. Interface de ﺡ،ﺡ loopbackﺡ ﺡﭨ▲
Toutes les implﺣ۸mentations d'IP supportent une interface de type ﺡ،ﺡ loopbackﺡ ﺡﭨ. L'objet de cette interface est de pouvoir utiliser les outils du rﺣ۸seau en local, sans passer par une interface rﺣ۸seau rﺣ۸elle (associﺣ۸e ﺣ une carte physique).
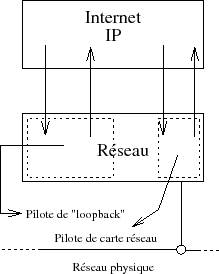
La figure IV.22 ci-dessus, montre que la couche IP peut utiliser, selon le routage, l'interface standard du rﺣ۸seau, oﺣﺗ l'interface de loopback.
Le routage est ici bien sﺣﭨr basﺣ۸ sur l'adresse IP associﺣ۸e ﺣ chacune des interfaces. Cette association est effectuﺣ۸e sur une machine Unix ﺣ l'aide de la commande ifconfig, qui ﺣ۸tablit une correspondance entre un pilote de pﺣ۸riphﺣ۸rique (repﺣ۸rﺣ۸ par son fichier spﺣ۸cial) et une adresse IP.
Dans le cas du pilote de loopback, l'adresse est standardisﺣ۸e ﺣ n'importe quelle adresse valide du rﺣ۸seau 127.
La valeur courante est 127.0.0.1, d'oﺣﺗ l'explication de la ligne ci-dessous dﺣ۸jﺣ rencontrﺣ۸e dans le cadre de la table de routageﺡ :
Routing tables
Internet:
Destination Gateway Flags Netif
...
127.0.0.1 127.0.0.1 UH lo0
...Dans toutes les machines Unix modernes, cette configuration est dﺣ۸jﺣ prﺣ۸vue d'emblﺣ۸e dans les scripts de dﺣ۸marrage.
Concrﺣ۷tement, tout dialogue entre outils clients et serveurs sur une mﺣ۹me machine est possible et mﺣ۹me souhaitable sur cette interface pour amﺣ۸liorer les performances et parfois la sﺣ۸curitﺣ۸(53).
L'exemple d'usage le plus marquant est sans doute celui du serveur de noms qui tient compte explicitement de cette interface dans sa configuration.
5-7. Finalement, comment ﺣ۶a marcheﺡ ?▲
Dans ce paragraphe nous reprenons la figure III.06 et nous y apportons comme cela ﺣ۸tait annoncﺣ۸ une explication du fonctionnement qui tienne compte des protocoles principaux examinﺣ۸s dans ce chapitre. Pour cela nous utilisons deux rﺣ۸seaux privﺣ۸s de la RFC 1918: 192.168.10.0 et 192.168.20.0 et nous faisons l'hypothﺣ۷se que la passerelle fonctionne comme une machine Unix qui ferait du routage entre deux de ses interfacesﺡ !
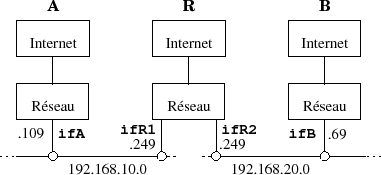
Ce tableau rﺣ۸sume l'adressage physique et logique de la situationﺡ :
| Interface | Adresse MAC | Adresse IP |
| ifA | 08:00:20:20:cf:af | 192.168.10.109 |
| ifB | 00:01:e6:a1:07:64 | 192.168.20.69 |
| ifR1 | 00:06:5b:0f:5a:1f | 192.168.10.249 |
| ifR2 | 00:06:5b:0f:5a:20 | 192.168.20.249 |
Nous faisons en outre les hypothﺣ۷ses suivantesﺡ :
- Les caches ﺡ،ﺡ arpﺡ ﺡﭨ des machines A, B et R sont vides.
- La machine A a connaissance d'une route vers le rﺣ۸seau 192.168.20 passant par 192.168.10.249 et rﺣ۸ciproquement la machine B voit le rﺣ۸seau 192.168.10.0 via le 192.168.20.249
- La machine A a connaissance de l'adresse IP de la machine B.
La machine A envoie un datagramme ﺣ la machine B, que se passe-t-il sur le rﺣ۸seauﺡ ?
ﺣtape 1
- La machine A applique l'algorithme de routage et s'aperﺣ۶oit que la partie rﺣ۸seau de l'adresse de B n'est pas dans le mﺣ۹me LAN (192.168.10/24 et 192.168.20/20 diffﺣ۷rent).
- L'hypothﺣ۷se 2 entraﺣ؟ne qu'une route existe pour atteindre ce rﺣ۸seau, passant par R. L'adresse IP de R est dans le mﺣ۹me LAN, A peut donc atteindre R par un routage direct. La consﺣ۸quence de l'hypothﺣ۷se 1 implique que pour atteindre R directement il nous faut d'abord dﺣ۸terminer son adresse physique. Le protocole ARP doit ﺣ۹tre utilisﺣ۸.
- A envoie en consﺣ۸quence une trame ARP comportant les ﺣ۸lﺣ۸ments suivantsﺡ :
| SENDER HA | 08:00:20:20:cf:af |
| SENDER ADR | 192.168.10.109 |
| TARGET HA | ff:ff:ff:ff:ff:ff |
| TARGET ADR | 192.168.10.249 |
- Avec un champ OPERATION qui contient la valeur 1, comme ﺡ،ﺡ question ARPﺡ ﺡﭨ.
- Remarquez qu'ici l'adresse IP destination est celle de Rﺡ !
ﺣtape 2
- R rﺣ۸pond ﺣ la ﺡ،ﺡ question ARPﺡ ﺡﭨ par une ﺡ،ﺡ rﺣ۸ponse ARPﺡ ﺡﭨ (OPERATION contient 2) et un champ complﺣ۸tﺣ۸ﺡ :
| SENDER HA | 00:06:5b:0f:5a:1f |
| SENDER ADR | 192.168.10.249 |
| TARGET HA | 08:00:20:20:cf:af |
| TARGET ADR | 192.168.10.109 |
ﺣtape 3
- A est en mesure d'envoyer son datagramme ﺣ B en passant par R. Il s'agit de routage indirect puisque l'adresse de B n'est pas sur le mﺣ۹me LAN. Les adresses physiques et logiques se rﺣ۸partissent maintenant comme ceciﺡ :
| IP SOURCE | 192.168.10.109 |
| IP TARGET | 192.168.20.69 |
| MAC SOURCE | 08:00:20:20:cf:af |
| MAC TARGET | 00:06:5b:0f:5a:1f |
- Remarquez qu'ici l'adresse IP destination est celle de Bﺡ !
ﺣtape 4
- R a reﺣ۶u le datagramme depuis A et ﺣ destination de B. Celle-ci est sur un LAN dans lequel R se trouve ﺣ۸galement, un routage direct est donc le moyen de transfﺣ۸rer le datagramme. Pour la mﺣ۹me raison qu'ﺣ l'ﺣ۸tape 1, R n'a pas l'adresse MAC de B et doit utiliser ARP pour obtenir cette adresse. Voici les ﺣ۸lﺣ۸ments de cette ﺡ،ﺡ question ARPﺡ ﺡﭨﺡ :
| SENDER HA | 00:06:5b:0f:5a:20 |
| SENDER ADR | 192.168.20.249 |
| TARGET HA | ff:ff:ff:ff:ff:ff |
| TARGET ADR | 192.168.20.69 |
ﺣtape 5
- Et la ﺡ،ﺡ rﺣ۸ponse ARPﺡ ﺡﭨﺡ :
| SENDER HA | 00:01:e6:a1:07:64 |
| SENDER ADR | 192.168.20.69 |
| TARGET HA | 00:06:5b:0f:5a:20 |
| TARGET ADR | 192.168.20.249 |
ﺣtape 6
- Enfin, dans cette derniﺣ۷re ﺣ۸tape, R envoie le datagramme en provenance de A, ﺣ Bﺡ :
| IP SOURCE | 192.168.10.109 |
| IP TARGET | 192.168.20.69 |
| MAC SOURCE | 00:06:5b:0f:5a:20 |
| MAC TARGET | 00:01:e6:a1:07:64 |
- Comparons avec le datagramme de l'ﺣ۸tape 3. Si les adresses IP n'ont pas changﺣ۸, les adresses MAC, diffﺣ۷rent complﺣ۷tementﺡ !
Remarqueﺡ : si A envoie un deuxiﺣ۷me datagramme, les caches ARP ont les adresses MAC utiles et donc les ﺣ۸tapes 1, 2, 4 et 5 deviennent inutiles...
5-8. Conclusion sur IP▲
Aprﺣ۷s notre tour d'horizon sur IPv4 nous pouvons dire en conclusion que son espace d'adressage trop limitﺣ۸ n'est pas la seule raison qui a motivﺣ۸ les travaux de recherche et dﺣ۸veloppement d'IPv6ﺡ :
- Son entﺣ۹te comporte deux problﺣ۷mes, la somme de contrﺣﺑle (checksum) doit ﺣ۹tre calculﺣ۸e ﺣ chaque traitement de datagramme, chaque routeur doit analyser le contenu du champ option.
- Sa configuration nﺣ۸cessite au moins trois informations que sont l'adresse, le masque de sous-rﺣ۸seau et la route par dﺣ۸faut.
- Son absence de sﺣ۸curitﺣ۸ est insupportable. Issu d'un monde fermﺣ۸ oﺣﺗ la sﺣ۸curitﺣ۸ n'ﺣ۸tait pas un problﺣ۷me, le datagramme de base n'offre aucun service de confidentialitﺣ۸, d'intﺣ۸gritﺣ۸ et d'authentification.
- Son absence de qualitﺣ۸ de service ne rﺣ۸pond pas aux exigences des protocoles applicatifs modernes (tﺣ۸lﺣ۸phonie, vidﺣ۸o, jeux interactifs en rﺣ۸seau... ). Le champ TOS n'est pas suffisant et surtout est interprﺣ۸tﺣ۸ de maniﺣ۷re inconsistante par les ﺣ۸quipements.
5-9. Bibliographie▲
Pour en savoir plusﺡ :
- RFC 791ﺡ : ﺡ،ﺡ Internet Protocol.ﺡ ﺡﭨ J. Postel. Sep-01-1981. (Format: TXT=97779 bytes) (Obsoletes RFC0760) (Status: STANDARD)
- RFC 826ﺡ : ﺡ،ﺡ Ethernet Address Resolution Protocol: Or converting network protocol addresses to 48.bit Ethernet address for transmission on Ethernet hardware.ﺡ ﺡﭨ D.C. Plummer. Nov-01-1982. (Format: TXT=22026 bytes) (Status: STANDARD)
- RFC 903ﺡ : ﺡ،ﺡ Reverse Address Resolution Protocol.ﺡ ﺡﭨ R. Finlayson, T. Mann, J.C. Mogul, M. Theimer. Jun-01-1984. (Format: TXT=9345 bytes) (Status: STANDARD)
- RFC 950ﺡ : ﺡ،ﺡ Internet Standard Subnetting Procedure.ﺡ ﺡﭨ J.C. Mogul, J. Postel. Aug-01-1985. (Format: TXT=37985 bytes) (Updates RFC0792) (Status: STANDARD)
- RFC 1112ﺡ : ﺡ،ﺡ Host extensions for IP multicasting.ﺡ ﺡﭨ S.E. Deering. Aug-01-1989. (Format: TXT=39904 bytes) (Obsoletes RFC0988, RFC1054) (Updated by RFC2236) (Also STD0005) (Status: STANDARD)
- RFC 1256ﺡ : ﺡ،ﺡ ICMP Router Discovery Messages. S. Deering.ﺡ ﺡﭨ Sep-01-1991. (Format: TXT=43059 bytes) (Also RFC0792) (Status: PROPOSED STANDARD)
- W. Richard Stevens - TCP/IP Illustrated, Volume 1 - The protocols - Addison-Wesley
- Douglas Comer - Internetworking with TCP/IP - Principles, protocols, and architecture - Prentice-Hall
- Craig Hunt - TCP/IP Network Administration - O'Reilly & Associates, Inc.
- Christian Huitema - Le routage dans l'Internet - EYROLLES