


16. Anatomie d'un serveur Web▲
16-1. Le protocole HTTP▲
ATTENTION CE CHAPITRE N'A PAS FAIT L'OBJET D'UNE REVISION DEPUIS DE NOMBREUSES ANNĂES. LES INFORMATIONS CONTENUES Y SONT JUSTES, MAIS PASSABLEMENT OBSOLĂTESÂ !
Ce document est une prĂŠsentation succincte du protocole HTTP 1.0 et du serveur Apache qui l'utilise.
Le protocole HTTP(193) est le protocole d'application utilisĂŠ pour vĂŠhiculer, entre autres, du HTML(194) sur l'Internet.
C'est le protocole le plus utilisÊ en volume depuis 1995, devant FTP, NNTP et SMTP ; il accompagne l'explosion de l'utilisation du système global d'information  World-Wide Web .
Depuis 1990, date d'apparition du  Web , le protocole HTTP Êvolue doucement, mais sÝrement. Il est longtemps restÊ sous la forme de  draft . La première version dÊployÊe largement a ÊtÊ la 1.0, dÊfinie dans la RFC 1945 de mai 1996. Depuis le dÊbut du mois de janvier 1997 est apparue la version 1.1, deux fois plus volumineuse pour tenir compte des nouvelles orientations de l'usage du service.
Aujourd'hui ce protocole est tellement rÊpandu que pour bon nombre de nouveaux utilisateurs du rÊseau, l'Internet c'est le  web  !
Techniquement, l'usage de ce protocole se conçoit comme une relation entre un client et un serveur. Le client, appelÊ gÊnÊriquement un  browser , un  User Agent , ou encore butineur de toile, interroge un serveur connu par son  URL(195)  dont la syntaxe est bien dÊcrite dans la RFC 1738.
Par exemple la chaÎne de caractères http://www.sio.ecp.fr/ est une URL ; il suffit de la transmettre en tant qu'argument à un quelconque outil d'exploration et celui-ci vous renverra (si tout se passe comme prÊvu !) ce qui est prÊvu sur le serveur en question pour rÊpondre à cette demande (car il s'agit bien d'une requête comme nous le verrons plus loin dans ce chapitre).
Le serveur, supposÊ à l'Êcoute du rÊseau au moment oÚ la partie cliente l'interroge, utilise un port connu à l'avance. Le port 80 est dÊdiÊ officiellement au protocole HTTP(196), mais ce n'est pas une obligation (cette dÊcision est prise à la configuration du serveur). L'URL qui dÊsigne un serveur peut contenir dans sa syntaxe le numÊro de port sur lequel il faut l'interroger, comme dans :
- http://www.sio.ecp.fr:11235/
16-1-1. Exemple d'ĂŠchange avec HTTP▲
Le transport des octets est assurÊ par TCP et le protocole est  human readable , ce qui nous autorise des essais de connexion avec le client TCP à tout faire : Telnet ! Bien entendu on pourrait utiliser un  browser  plus classique, mais celui-ci gÊrant pour nous le dÊtail des Êchanges il ne serait plus possible de les examiner.
$ Telnet localhost 80
Trying...
Connected to localhost.
Escape character is '^]'.Ce qui est tapĂŠ par l'utilisateur et la rĂŠponse du serveur.
GET / HTTP/1.0La requĂŞte, suivie d'une ligne vide.
HTTP/1.1 200 OK
Date: Fri, 01 Mar 2002 10:59:06 GMT
Server: Apache/1.3.23 (Unix)
Last-Modified: Sat, 10 Nov 2001 16:13:02 GMT
ETag: "1381-8b-3bed520e"
Accept-Ranges: bytes
Content-Length: 79
Connection: close
Content-Type: text/html
<HTML>
<HEAD>
<TITLE>Ceci est un titre</TITLE>
</HEAD>
<BODY>
</BODY>
</HTML>
Connection closed by foreign host.Enfin la rÊponse du serveur, que l'on peut dÊcomposer en trois parties :
- Un code de retour (HTTP)Â ;
- Un entĂŞte MIMEÂ ;
- Des octets, ici ceux d'une page ĂŠcrite en HTML.
Notons ĂŠgalement la dĂŠconnexion Ă l'initiative du serveur, en fin d'envoi de la page HTML.
16-1-2. Structure d'un ĂŠchange▲
L'exemple qui prÊcède est typique d'un Êchange entre le client et le serveur : une question du client gÊnère une rÊponse du serveur, le tout lors d'une connexion TCP qui se termine lors de l'envoi du dernier octet de la rÊponse (clôture à l'initiative du serveur).
Le serveur ne conserve pas la mÊmoire des Êchanges passÊs, on dit aussi qu'il est sans Êtat, ou  stateless .
La question et la rÊponse sont bâties sur un modèle voisin : le message HTTP.
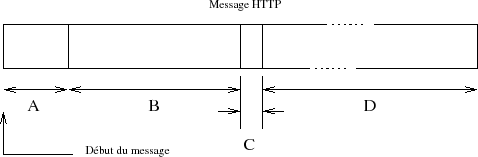
Les parties A, B et C forment l'entĂŞte du message, et D le corps.
à la première ligne du message est soit la question posÊe ( request-line ), soit le statut de la rÊponse ( status-line ).
- La question est une ligne terminÊe par CRLF, elle se compose de trois champs : une mÊthode à prendre dans GET, HEAD, ou POST :
- GET Plus de 99 % des requĂŞtes ont cette mĂŠthode, elle retourne l'information demandĂŠe dans l'URL (ci-dessous),
- HEAD La mĂŞme chose que GET, mais seul l'entĂŞte du serveur est envoyĂŠ. Utile pour faire des tests d'accessibilitĂŠ sans surcharger la bande passante. Utile ĂŠgalement pour vĂŠrifier de la date de fraicheur d'un document (information contenue dans l'entĂŞte),
- POST Cette mÊthode permet d'envoyer de l'information au serveur, c'est typiquement le contenu d'un formulaire rempli par l'utilisateur ;
- une ressource que l'on dĂŠsigne par une URL(197). Par exemple http://www.site.org/;
- la version du protocole, sous la forme HTTP-NumĂŠro de version. Par exemple HTTP/1.1Â !
- La rÊponse. Cette première ligne n'est que le statut de la rÊponse, les octets qui la dÊtaillent se trouvent plus loin, dans le corps du message. Trois champs la composent, elle se termine par CRLF :
- La version du protocole, sous forme HTTP-NumĂŠro de version, comme pour la question.
- Statut C'est une valeur numÊrique qui dÊcrit le statut de la rÊponse. Le premier des trois digits donne le sens gÊnÊral :
- 1xx N'est pas utilisÊ  Futur Use 
- 2xx Succès, l'action demandÊe a ÊtÊ comprise et exÊcutÊe correctement.
- 3xx Redirection. La partie cliente doit reprendre l'interrogation, avec une autre formulation.
- 4xx Erreur cĂ´tĂŠ client. La question comporte une erreur de syntaxe ou ne peut ĂŞtre acceptĂŠe.
- 5xx Erreur cĂ´tĂŠ serveur. Il peut s'agir d'une erreur interne, due Ă l'OS ou Ă la ressource devenue non accessible.
- Phrase C'est un petit commentaire ( Reason- Phrase ) qui accompagne le statut, par exemple le statut 200 est suivi gÊnÊralement du commentaire  OK  !
B C'est une partie optionnelle, qui contient des informations Ă propos du corps du message. Sa syntaxe est proche de celle employĂŠe dans le courrier ĂŠlectronique, et pour cause, elle respecte aussi le standard MIME(198).
- Un entête de ce type est constituÊ d'une suite d'une ou plusieurs lignes (la fin d'une ligne est le marqueur CRLF) construite sur le modèle :
- Nom de champ : Valeur du champ CRLF
- ĂŠventuellement le marqueur de fin de ligne peut ĂŞtre omis pour le sĂŠparateur ÂŤÂ ;Â Âť.
- Exemple d'entĂŞte MIMEÂ :
2.
3.
4.
5.
6.
7.
8.
Date: Fri, 01 Mar 2002 10:59:06 GMT
Server: Apache/1.3.23 (Unix)
Last-Modified: Sat, 10 Nov 2001 16:13:02 GMT
ETag: "1381-8b-3bed520e"
Accept-Ranges: bytes
Content-Length: 79
Connection: close
Content-Type: text/html
- Date : C'est la date à laquelle le message a ÊtÊ envoyÊ. Bien sÝr il s'agit de la date du serveur, il peut exister un dÊcalage incohÊrent si les machines ne sont pas synchronisÊes (par exemple avec XNTP).
- Server : Contient une information relative au serveur qui a fabriquÊ la rÊponse. En gÊnÊral, la liste des outils logiciels et leur version.
- Content-type : Ce champ permet d'identifier les octets du corps du message.
- Content-length : DÊsigne la taille (en octets) du corps du message, c'est-à -dire la partie D de la figure XV.1.
- Last-modified : Il s'agit de la date de dernière modification du fichier demandÊ, comme l'illustre le rÊsultat de la commande ll (voir aussi la coïncidence de la taille du fichier et la valeur du champ prÊcÊdent).
-rw-r--r-- 1 web doc 139 Nov 10 17:13 index.html
- ETag : C'est un identificateur du serveur, constant lors des Êchanges. C'est un moyen de maintenir le dialogue avec un serveur en particulier, par exemple quand ceux-ci sont en grappe pour Êquilibrer la charge et assurer la redondance.
C Une ligne vide (CRLF) qui est le marqueur de fin d'entĂŞte. Il est donc absolument obligatoire qu'elle figure dans le message. Son absence entraĂŽne une incapacitĂŠ de traitement du message, par le serveur ou par le client.
D Le corps du message. Il est omis dans certains cas, comme une requĂŞte avec la mĂŠthode GET ou une rĂŠponse Ă une requĂŞte avec la mĂŠthode HEAD.
- C'est dans cette partie du message que l'on trouve par exemple les octets du HTML, ou encore ceux d'une image...
- Le type des octets est intimement liĂŠ Ă celui annoncĂŠ dans l'entĂŞte, plus prĂŠcisĂŠment dans le champ Content-Type.
- Par exemple :
Content-Type : text/html =) Le corps du message contient des octets Ă interprĂŠter comme ceux d'une page ĂŠcrite en HTML.
Content-Type : image/jpg =) Le corps du message contient des octets Ă interprĂŠter comme ceux d'une image au format jpeg16-2. URI et URL▲
Le succès du  web  s'appuie largement sur un système de nommage des objets accessibles, qui en uniformise l'accès, qu'ils appartiennent à la machine sur laquelle on travaille ou distants sur une machine en un point quelconque du rÊseau (mais supposÊ accessible). Ce système de nommage universel est l'URL ( Uniform Resource Locator  - RFC 1738) dÊrivÊ d'un système de nommage plus gÊnÊral nommÊ URI ( Universal Resource Identifier  - RFC 1630).
La syntaxe gÊnÊrale d'une URL est de la forme :
- <scheme>Â :<scheme-specific-part>
Succintement la  scheme  est une mÊthode que l'on sÊpare à l'aide du caractère  :  d'une chaÎne de caractères ASCII 7 bits dont la structure est essentiellement fonction de la  scheme  qui prÊcède et que l'on peut imaginer comme un argument.
Une  scheme  est une sÊquence de caractères 7 bits. Les lettres  a  à  z , les chiffres de  0  à  9 , le signe  + , le  .  et le  -  sont admis. Majuscules et minuscules sont indiffÊrenciÊes.
Exemples de  schemes  : http, FTP, file, mailto... Il en existe d'autres (cf la RFC) non indispensables pour la comprÊhension de cet exposÊ.
Globalement une URL doit être encodÊe en ASCII 7 bits(199) sans caractère de contrôle (c'est-à -dire entre les caractères 20 et 7F), ce qui a comme consÊquence que tous les autres caractères doivent être encodÊs.
La mÊthode d'encodage transforme tout caractère non utilisable directement en un triplet formÊ du caractère  %  et de deux caractères qui en reprÊsente la valeur hexadÊcimale. Par exemple l'espace (20 hex) doit être codÊ .
Un certain nombre de caractères, bien que thÊoriquement reprÊsentables, sont considÊrÊs comme non sÝrs ( unsafe ) et devraient être Êgalement encodÊs de la même manière que ci-dessus, ce sont :
- % < > " # { } | \ ^ ~ [ ] `
Pour un certain nombre de  schemes  (http...) certains caractères sont rÊservÊs car ils ont une signification particulière. Ce sont :
- ; / ? : @ = &
Ainsi, s'ils apparaissent dans l'URL sans faire partie de sa syntaxe, ils doivent ĂŞtre encodĂŠs.
16-2-1. Scheme HTTP▲
Une URL avec la  scheme  HTTP bien formÊe doit être de la forme :
- http://$<$host$>$:$<$port$>$/$<$path$>$?$<$searchpath$>$
-  path  et  searchpath  sont optionnels.
- host C'est un nom de machine ou une adresse IP.
- port Le numĂŠro de port. S'il n'est pas prĂŠcisĂŠ, la valeur 80 est prise par dĂŠfaut.
- path C'est un sĂŠlecteur au sens du protocole HTTP.
- searchpath C'est ce que l'on appelle la  query string , autrement dit la chaÎne d'interrogation.
- à l'intÊrieur de ces deux composantes, les caractères / ; ? sont rÊservÊs, ce qui signifie que s'ils doivent être employÊs, ils doivent être encodÊs pour Êviter les ambiguïtÊs.
-  path  et  searchpath  sont optionnels.
- host C'est un nom de machine ou une adresse IP.
- port Le numĂŠro de port. S'il n'est pas prĂŠcisĂŠ, la valeur 80 est prise par dĂŠfaut.
- path C'est un sĂŠlecteur au sens du protocole HTTP.
- searchpath C'est ce que l'on appelle la  query string , autrement dit la chaÎne d'interrogation.
- à l'intÊrieur de ces deux composantes, les caractères / ; ? sont rÊservÊs, ce qui signifie que s'ils doivent être employÊs, ils doivent être encodÊs pour Êviter les ambiguïtÊs.
Le ? marque la limite entre l'objet interrogeable et la  query string . à l'intÊrieur de cette chaÎne d'interrogation, le caractère + est admis comme raccourci pour l'espace (ASCII 20 hex). Il doit donc être encodÊ s'il doit être utilisÊ en tant que tel.
De même, à l'intÊrieur de la  query string  le caractère = marque la sÊparation entre variable et valeur, le & marque la sÊparation entre les couples variable = valeur.
Exemple rÊcapitulatif :
http://www.google.fr/search?q=cours+r?seaux\&hl=fr\&start=10\&sa=N
Notez le  Ê  codÊ ?, c'est-à -dire le caractère de rang 14x16+9 = 233.
On peut ĂŠgalement observer quatre variables q, hl, start et sa dont la signification peut ĂŞtre partiellement devinĂŠe, mais dont le remplissage reste Ă la charge du serveur en question.
Le rôle de la chaÎne  search  est celui de ce que l'on appelle une CGI ou  Common Gateway Interface , c'est-à -dire un programme qui effectue le lien entre le serveur interrogÊ et des programmes d'application, ici une recherche dans une base de donnÊes. Nous examinons succinctement le principe de fonctionnement de tels programmes.
16-3. Architecture interne du serveur Apache▲
Cette partie se consacre Ă l'ĂŠtude du fonctionnement du serveur Apache(200).
Pour comprendre les mĂŠcanismes internes d'un tel serveur il est absolument nĂŠcessaire de pouvoir en lire le code source, cette contrainte exclut les produits commerciaux.
Au mois de mars 2002, d'après le  Netcraft Web Server Survey(201)  le serveur le plus utilisÊ (55 %) est très majoritairement celui du projet Apache.
D'après ses auteurs, le serveur Apache est une solution de continuitÊ au serveur du NCSA(202). Il corrige des bogues et ajoute de nombreuses fonctionnalitÊs, particulièrement un mÊcanisme d'API pour permettre aux administrateurs de sites de dÊvelopper de nouveaux modules adaptÊs à leurs besoins propres.
Plus gÊnÊralement, tout ce qui n'est pas strictement dans les attributions du serveur (gestion des processus, gestion mÊmoire, gestion du rÊseau) est traitÊ comme un module d'extension. Le fichier apache 1.3.23/htdocs/manual/misc/API.html de la distribution standard apporte des prÊcisions, le serveur http://www.apacheweek.com/ pointe Êgalement sur grand nombre de documents très utiles.
Le serveur Apache introduit ĂŠgalement la possibilitĂŠ de serveurs multidomaines (domaines virtuels), ce qui est fort apprĂŠciĂŠ des hĂŠbergeurs de sites.
16-3-1. Environnement d'utilisation▲
La figure XV.2 qui suit, synthĂŠtise l'environnement d'utilisation.
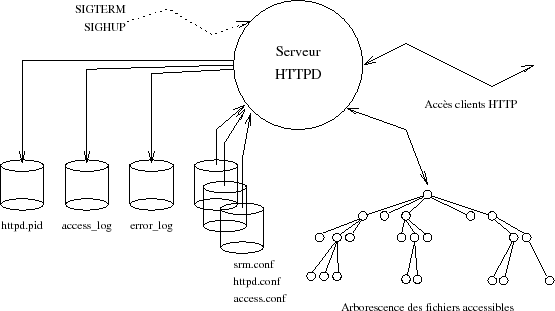
Le serveur se met en Ĺuvre simplement. La compilation fournit un exĂŠcutable, httpd, qui, pour s'exĂŠcuter correctement, a besoin des trois fichiers ASCII de configuration : srm.conf, access.conf, httpd.conf.
C'est en fait dans celui-ci que sont effectuĂŠs l'essentiel des ajustements locaux Ă la configuration standard.
Lors de l'exĂŠcution, trois fichiers sont modifiĂŠs(203)Â :
- httpd.pid (PidFile) contient le  process ID  du  leader  de groupe ; à utiliser avec le signal SIGHUP (cf figure XV.2) pour provoquer la relecture et le redÊmarrage  à chaud  du serveur, ou avec SIGTERM pour mettre fin à son activitÊ.
- access log (CustomLog) Qui contient le dÊtail des accès clients. Ce fichier peut devenir très volumineux.
- error log (ErrorLog) Qui contient le dÊtail des accès infructueux et des Êventuels problèmes de fonctionnement du serveur.
Le  daemon  httpd est soit du type (ServerType)  standalone  ou si son invocation est occasionnelle, à la demande pilotÊ par inetd.
Il dÊmarre son activitÊ par ouvrir le port (Port) dÊsignÊ dans la configuration, puis s'exÊcute avec les droits de l'utilisateur User et du groupe Group. Sa configuration se trouve dans le rÊpertoire conf sous-rÊpertoire de ServerRoot. Les fichiers accessibles par les connexions clientes, eux, se situent dans le rÊpertoire DocumentRoot qui en est la racine, c'est-à -dire vue comme /  par les browsers clients.
Le fichier httpd.pid contient un numÊro de processus  leader  de groupe car en fait le serveur Apache, dès son initialisation, dÊmarre un certain nombre de processus, autant de serveurs capables de comprendre les requêtes des clients. En voici un exemple :
- MinSpareServers 5 C'est le nombre minimum d'instances du serveur (non compris le processus maĂŽtre) en attente d'une connexion. S'il en manque, elles sont crĂŠĂŠes.
- MaxSpareServers 10 C'est le nombre maximum d'instances du serveur (non compris le processus maĂŽtre) en attente d'une connexion. S'il y en a de trop elles sont supprimĂŠes.
- StartServers 5 C'est le nombre minimum d'instances du serveur (non compris le processus maĂŽtre) au dĂŠmarrage.
- MaxClients 150 C'est le nombre maximum de clients (requĂŞtes HTTP) simultanĂŠs. Cette constante peut ĂŞtre augmentĂŠe en fonction de la puissance de la machine.
Un processus joue le rôle de rÊgulateur, du point de vue Unix c'est un processus chef de groupe ( leader ). La commande ps permet de visualiser une situation opÊrationnelle :
web 17361 2794 0 Mar 13 ? 0:00 /usr/local/bin/httpd -d /users/web
root 2794 1 0 Feb 23 ? 0:06 /usr/local/bin/httpd -d /users/web
web 17363 2794 0 Mar 13 ? 0:00 /usr/local/bin/httpd -d /users/web
web 17270 2794 0 Mar 13 ? 0:01 /usr/local/bin/httpd -d /users/web
web 17362 2794 0 Mar 13 ? 0:00 /usr/local/bin/httpd -d /users/web
web 17401 2794 0 Mar 13 ? 0:00 /usr/local/bin/httpd -d /users/web
web 17313 2794 0 Mar 13 ? 0:00 /usr/local/bin/httpd -d /users/web
web 17312 2794 0 Mar 13 ? 0:01 /usr/local/bin/httpd -d /users/web
web 17355 2794 0 Mar 13 ? 0:00 /usr/local/bin/httpd -d /users/web
web 17314 2794 0 Mar 13 ? 0:01 /usr/local/bin/httpd -d /users/webIci il y a neuf instances du serveur et le processus maÎtre, qu'il est aisÊ de reconnaitre (2794) car il est le père des autres processus (ce qui n'implique pas qu'il en est le chef de groupe, mais la suite de l'analyse nous le confirmera).
La commande netstat -f inet -a | grep http ne donne qu'une ligne :
TCP 0 0 *.http *.* LISTENCela signifie qu'aucune connexion n'est en cours sur ce serveur, et qu'une seule  socket  est en apparence à l'Êcoute du rÊseau. C'est une situation qui peut sembler paradoxale eu Êgard au nombre de processus ci-dessus, le code nous fournira une explication au paragraphe suivant.
La commande tail -1 logs/access.log fournit la trace de la dernière requête :
www.chezmoi.tld - - [01/Mar/2002:17:13:28 +0100] "GET / HTTP/1.0" 200 79Il s'agit de la trace de notre exemple d'interrogation du dÊbut de ce chapitre !
16-3-2. Architecture interne▲
Attention, ce paragraphe concerne la version 1.1.1 du logiciel. Le fonctionnement de la version courante, 1.3.23, reste similaire, mais le code ayant beaucoup changÊ, les numÊros de lignes sont devenus de fait complètement faux.
Ce qui nous intÊresse plus particulièrement pour expliquer le fonctionnement du serveur se trouve dans le rÊpertoire src/, sous rÊpertoire du rÊpertoire principal de la distribution :
$ ll apache_1.1.1/
total 19
-rw------- 1 fla users 3738 Mar 12 1996 CHANGES
-rw------- 1 fla users 2604 Feb 22 1996 LICENSE
-rw------- 1 fla users 3059 Jul 3 1996 README
drwxr-x--- 2 fla users 512 Feb 7 22:14 CGI-bin
drwxr-x--- 2 fla users 512 Feb 7 22:14 conf
drwxr-x--- 2 fla users 512 Feb 7 22:14 htdocs
drwxr-x--- 2 fla users 2048 Feb 7 22:14 icons
drwxr-x--- 2 fla users 512 Jul 8 1996 logs
drwxr-x--- 2 fla users 2048 Mar 12 10:42 src
drwxr-x--- 2 fla users 512 Feb 7 22:15 supportDans ce rĂŠpertoire qui compte au moins 75 fichier (wc -l *.[ch] ) 27441 lignes) nous nous restreignons aux fichiers essentiels dĂŠcrits dans le ÂŤÂ READMEÂ Âť soit encore une petite dizaine d'entre eux (wc -l ) 6821 lignes)Â : mod CGI.c, http protocol.c, http request.c, http core.c, http config.c, http log.c, http main.c, alloc.c
Dans un premier temps nous allons examiner le fonctionnement de la gestion des processus, du mode de relation entre le père et ses fils.
Puis, dans un autre paragraphe, nous examinerons plus particulièrement ce qui se passe lors d'une connexion, avec le cas particulier de l'exÊcution d'une CGI(204) qui comme son nom l'indique est le programme qui effectue l'interface entre le serveur HTTP et un programme d'application quelconque.
Dans la suite de ce document, le terme ÂŤÂ CGIÂ Âť employĂŠ seul dĂŠsigne ce type d'application.
16-3-2-1. Gestion des processus▲
Au commencement est le main, et celui-ci se trouve dans le fichier http main.c, comme il se doit !
... ...
1035 pool *pconf; /* Pool for config stuff */
1036 pool *ptrans; /* Pool for per-transaction stuff */
... ...
1472 int
1473 main(int argc, char *argv[])
1474 {
... ...
1491 init_alloc();
1492 pconf = permanent_pool;
1493 ptrans = make_sub_pool(pconf);La fonction init alloc appelle make sub pool qui initialise un intÊressant mÊcanisme de buffers chaÎnÊs, utilisÊ tout au long du code dès lors qu'il y a besoin d'allouer de la mÊmoire.
Les diffĂŠrents modules du serveur sont ajoutĂŠs dans une liste chaĂŽnĂŠe.
... ...
1523 setup_prelinked_modules();
1524
1525 server_conf = read_config (pconf, ptrans, server_confname);
1526
1527 if(standalone) {
1528 clear_pool (pconf); /* standalone_main rereads... */
1529 standalone_main(argc, argv);
1530 }
1531 else {
... ...
1580 }
1581 exit (0);
1582 } Standalone  est à 0 si le serveur est invoquÊ depuis inetd(205). Son mode de fonctionnement le plus efficace reste avec ce paramètre à 1 (voir le cours sur inetd), que nous supposons ici.
- La fonction standalone main (ligne 1362) prÊpare le processus à son futur rôle de serveur. Pour bien comprendre le cette fonction, il faut imaginer qu'elle est invoquÊe au dÊmarrage, et  à chaud , pour lire et relire la configuration.
- Ligne 1369 , la variable one process = 0 (sinon le processus est en mode debug) occasionne l'appel à la fonction detach (ligne 876). Celle-ci transforme le processus en  leader  de groupe avec la succession bien connue fork + setsid (pour plus de dÊtails, voir le cours sur les daemons).
- Ligne 1374 , la fonction sigsetjmp enregistre la position de la pile et l'Êtat du masque d'interruption (deuxième argument non nul) dans restart buffer. Tout appel ultÊrieur à siglongjmp forcera la reprise de l'exÊcution en cette ligne.
- Ligne 1377 On ignore tout signal de type SIGHUP, cela bloque toute tentative cumulative de relecture de la configuration.
- Ligne 1382 (one process = 0) on envoie un signal SIGHUP à tous les processus du groupe. Cette disposition n'est utile que dans le cas d'un redÊmarrage  à chaud . La variable pgrp est initialisÊe par la fonction.
- detach (ligne 876), elle contient le PID du chef de groupe. L'intÊrêt d'avoir un groupe de processus est que le signal envoyÊ à son  leader  est automatiquement envoyÊ à tous les processus y appartenant. Chaque processus qui reçoit ce signal, s'il est en mesure de le traiter, appelle la fonction just die qui exÊcute un exit(0) (ligne 943). Donc tous les fils meurent, sauf le chef de groupe.
- Ligne 1390 , l'appel Ă la fonction reclaim child processes() effectue autant de wait qu'il y avait de processus fils, pour ĂŠviter les zombis.
- Ligne 1398 Relecture des fichiers de configuration.
- Ligne 1400 set group privs (ligne 960) change le  user id  et le  group id  si ceux-ci ont ÊtÊ modifiÊs.
- Ligne 1401 accept mutex init (ligne 166) fabrique un fichier temporaire (/usr/tmp/htlock.XXXXXX), l'ouvre, rÊduit son nombre de liens à 0, de telle sorte qu'il sera supprimÊ dès la fin du processus. Ce fichier est le verrou d'accès à la socket principale, comme nous l'examinerons un peu plus loin.
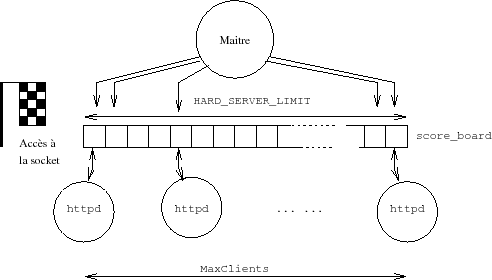
- Ligne 1402 reinit scoreboard (ligne 596) Cette fonction remet à zÊro, ou crÊe (setup shared mem ligne 432) la zone de mÊmoire commune entre le chef de groupe et ses processus fils. Cette zone mÊmoire est, soit un segment de mÊmoire partagÊe (IPC du système V), soit de la mÊmoire rendue commune par un appel à la primitive mmap (Le choix est effectuÊ par configure qui analyse les possibilitÊs du système, avant compilation du serveur). La taille de cette zone est de HARD SERVER LIMIT x sizeof(short score) octets, la structure short score, dÊfinie dans scoreboard.h, recueille les statistiques d'utilisation de chaque serveur et son statut (par exemple SERVER READY, SERVER DEAD...). C'est par ce moyen que le serveur maÎtre contrôle les serveurs fils. HARD SERVER LIMIT dÊfinit le nombre maximum de connexions actives, donc d'instances de serveur, à un instant donnÊ. En standard cette valeur est 150, elle peut être augmentÊe dans le fichier de configuration httpd.conf (voir ci-dessus au paragraphe II.1)
Enfin la figure XV.4 montre son rĂ´le stratĂŠgique.
- Ligne 1413 (on suppose listeners = NULL), après avoir initialisÊ une structure d'adresse, appel à la fonction make sock (ligne 1298). Celle-ci crÊe et initialise une socket, et, dÊtail important, appelle par deux fois setsockopt, ce qui mÊrite un commentaire :
... ...
1312 if((setsockopt(s, SOL_SOCKET,SO_REUSEADDR,(char *)&one,sizeof(one)))
1313 == -1) {
... ...
1318 if((setsockopt(s, SOL_SOCKET,SO_KEEPALIVE,(char *)&keepalive_value,
1319 sizeof(keepalive_value))) == -1) {
... ...-
- SO REUSEADDR Indique que la règle d'exclusivitÊ suivie par bind(2) pour l'attribution d'un port ne s'applique plus : un processus peut se servir d'un même port pour plusieurs usages diffÊrents (par exemple le client FTP qui attaque les ports 21 et 20 du serveur avec le même port local), voire des processus diffÊrents (c'est le cas ici) peuvent faire un bind avec le même port sans rencontrer la fatidique erreur 48 ( Address already in use ) !
Vu des clients HTTP, le serveur est accessible uniquement sur le port 80, ce que nous avons remarquÊ au paragraphe II.1 (netstat) sans l'expliquer, voilà qui est fait !
-
- SO KEEPALIVE Indique Ă la couche de transport, ici TCP, qu'elle doit ĂŠmettre Ă intervalle rĂŠgulier (non configurable) un message Ă destination de la socket distante. Que celle-ci n'y rĂŠponde pas et la prochaine tentative d'ĂŠcriture sur la socket se solde par la rĂŠception d'un SIGPIPE, indiquant la disparition de la socket distante (voir plus loin la gestion de ce signal dans la fonction child main, ligne 1139).
- Ligne 1430 set signals (1007) prÊvoit le comportement lors de la rÊception des signaux :
- SIGHUP Appel de restart
- SIGTERM Appel de sig term
- Ligne 1438 et la suivante, crĂŠation d'autant de processus fils qu'il en est demandĂŠ dans le fichier de configuration (StartServers). La fonction make child (1275) appelle fork, puis dans le fils modifie le comportement face aux signaux SIGHUP et SIGTERM (just die appelle exit) avant d'exĂŠcuter child main.
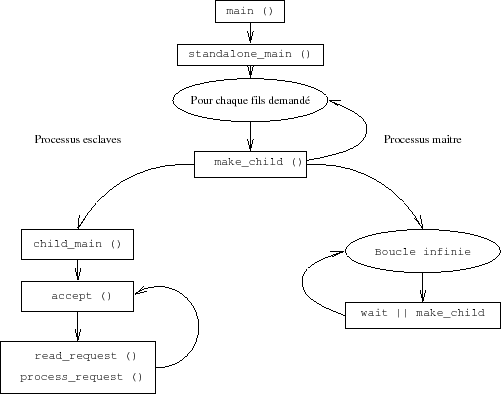
ArrivĂŠs Ă ce stade, il nous faut analyser l'attitude des deux types de processus.
Le processus maĂŽtre
- Ligne 1444 dĂŠmarre une boucle infinie de surveillance. Seule la rĂŠception et le traitement d'un signal peuvent l'interrompre.
- Ligne 1458 Ici, si le nombre de serveurs disponibles est infĂŠrieur au nombre minimal requis, il y rĂŠgĂŠnĂŠration de ceux qui manquent avec la fonction make child.
Les processus esclaves
- Ligne 1139 La gestion de ces processus, autant de serveurs Web opĂŠrationnels, dĂŠbute avec l'appel de la fonction child main.
- Ligne 1167 DÊbut de la boucle infinie qui gère cette instance du serveur. Au cours d'une boucle le serveur gère l'acceptation d'une requête et son traitement.
- Ligne 1174 Gestion du SIGPIPE donc des clients qui dÊconnectent avant l'heure !
- Ligne 1180 Si le nombre de serveurs libres (count idle servers) est supĂŠrieur Ă la limite configurĂŠe, ou si
- Ligne 1182 le nombre de requĂŞtes traitĂŠes par ce processus a atteint la limite max requests per child, le processus s'arrĂŞte de lui-mĂŞme. C'est l'autorĂŠgulation pour libĂŠrer des ressources occupĂŠes par un trop grand nombre de processus serveurs inutiles.
- Ligne 1190 L'appel à la fonction accept mutex on verrouille l'accès à la ressource dÊfinie prÊcÊdemment avec accept mutex init (ligne 166). Ce verrouillage est bloquant et exclusif. C'est-à -dire qu'il faut qu'un autre processus en dÊverrouille l'accès pour que le premier processus sur la liste d'attente (gÊrÊe par le noyau Unix) y accède.
Ce fonctionnement est assurĂŠ suivant la version d'Unix par la primitive flock ou par la primitive fcntl.
Les sĂŠmaphores du Système V (semget, semctl, semop...) assurent la mĂŞme fonctionnalitĂŠ, en plus complet, ils sont aussi plus complexes Ă mettre en Ĺuvre.
Cette opÊration est à rapprocher de l'option SO REUSEADDR prise ligne 1312. Il faut Êviter que plusieurs processus serveurs disponibles ne rÊpondent à la requête. Il n'y a qu'un seul processus prêt à rÊpondre à la fois et dès que le accept (ligne 1217) retourne dans le code utilisateur la ressource est dÊverrouillÊe (on suppose toujours listeners = 0).
- Ligne 1221 La fonction accept mutex off dÊverrouille l'accès à la socket.
- Ligne 1245 read request lit la requĂŞte du client, donc un message HTTP.
- Ligne 1247 process request fabrique la rĂŠponse au client, donc un autre message HTTP.
16-3-2-2. Prise en main des requĂŞtes▲
Le fichier concernĂŠ par la lecture de la requĂŞte est http protocol.c.
La lecture de la première ligne du message HTTP est assurÊe par la fonction read request line, ligne 329(206).
La lecture de l'entĂŞte MIME est assurĂŠe par la fonction get mime headers, ligne 356. Attention, seul l'entĂŞte est lu, le corps du message dans le cas de la mĂŠthode POST est lu plus tard, lors du traitement du message, par le programme d'application (CGI).
Le fichier concernĂŠ par la formulation de la rĂŠponse est http request.c et la fonction principale process request, ligne 772. Celle-ci appelle en cascade process request internal, ligne 684.
Cette dernière effectue un certain nombre de tests avant de traiter effectivement la requête. Parmi ceux-ci on peut relever,
- Ligne 716 La fonction unescape url (util.c, ligne 593) assure le dÊcodage des caractères rÊservÊs et transcodÊs comme il est spÊcifiÊ par la RFC 1738.
- Ligne 723 La fonction getparents filtre les chemins ( pathname ) qui prêtent à confusion.
- Ligne 768 La fonction invoke handler est le point d'entrĂŠe dans le traitement de la requĂŞte. Cette fonction (http config.c, ligne 267) invoque le programme (module) qui se charge de fabriquer la rĂŠponse, au vu du contenu du champ content type de la requĂŞte. Si celui est inexistant, comme dans notre exemple du paragraphe I, il est positionnĂŠ par dĂŠfaut Ă la valeur html/text.
16-3-2-3. Deux types de CGI▲
Pour la suite nous supposons que la prise en main de la requĂŞte est faite par le module ÂŤÂ CGIÂ Âť, dĂŠfini dans le fichier mod CGI.c. Le point d'entrĂŠe est la fonction CGI handler (ligne 207), c'est-Ă -dire celle qui appelĂŠe par invoke handler, vue au paragraphe ci-dessus.
La lecture du code permet de dĂŠduire qu'il y a deux types de CGI, la distinction est faite par le nom de la CGI elle-mĂŞme.
La figure XV.5 rĂŠsume les 2 situations possibles d'exĂŠcution d'une CGI.
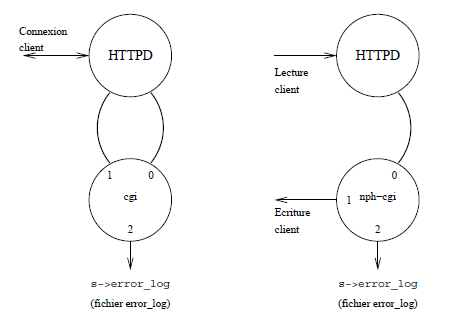
Si le nom de l'exÊcutable commence par nph-(207) le comportement du serveur http change. Dans le cas ordinaire (nom quelconque) les donnÊes transmises depuis le client vers la CGI et rÊciproquement, passent par le processus httpd et via un tube non nommÊ ( pipe ).
Dans le cas d'une CGI  nph , seules les donnÊes lues depuis le client (par exemple avec la mÊthode POST) transitent par le processus httpd, la rÊponse, elle, est Êmise directement, ce qui amÊliore les performances en Êvitant une sÊquence lecture/Êcriture inutile. Ce comportement est justifiÊ dès que de gros volumes d'octets sont à transmettre au client (de grandes pages HTML, des images...).
Attention, dans ce dernier cas, c'est Ă la CGI de fabriquer l'intĂŠgralitĂŠ du message HTTP, y compris l'entĂŞte MIME. Ă elle ĂŠgalement de gĂŠrer la dĂŠconnexion prĂŠmaturĂŠe du client (SIGPIPE).
Ces deux modes de fonctionnement ne sont pas clairement documentÊs, en fait il s'agit d'une caractÊristique du serveur du CERN, maintenue pour assurer sans doute la compatibilitÊ avec les applicatifs dÊjà Êcrits. Il n'est pas assurÊ que cette possibilitÊ existera dans les futures versions du serveur  Non Parse Header  Apache, notamment celles qui utiliseront la version 1.1 d'HTTP.
Examinons le code du fichier mod CGI.c :
207 int CGI_handler (request_rec *r)
208 {
209 int nph;
... ...
222 nph = !(strncmp(argv0,"nph-",4));
... ...
La variable nph vaut 1 si la CGI est de ce type.
... ...
251 add_common_vars (r);
... ...Ici on commence à fabriquer l'environnement d'exÊcution de la CGI Cette fonction (fichier util script.c, ligne 126) complète les variables qui ne dÊpendent pas du contenu de la requête, par exemple SERVER SOFTWARE, REMOTE HOST...
... ...
277 if (!spawn_child (r->connection->pool, CGI_child, (void *)&cld,
278 nph ? just_wait : kill_after_timeout,
279 &script_out, nph ? NULL : &script_in)) {
280 log_reason ("couldn't spawn child process", r->filename, r);
281 return SERVER_ERROR;
282 }
... ...L'appel de cette fonction provoque la crÊation d'un processus fils, celui qui finalement va exÊcuter la CGI. Il faut remarquer le deuxième argument qui est un pointeur de fonction (CGI child), et le sixième qui est nul dans le cas d'une CGI du type  nph .
script in et script out sont respectivement les canaux d'entrÊe et sortie des donnÊes depuis et vers le processus qui exÊcute la CGI. Il parait donc logique que dans le cas d'une CGI de type  nph  script in soit nul. Un mÊcanisme non encore analysÊ duplique la sortie de ce processus vers le client plutôt que vers le processus serveur.
Nous continuons la description du point de vue du processus père, donc httpd.
Ligne 295 et les suivantes, jusqu'à la ligne 332, le processus lit ce que le client lui envoie, si la mÊthode choisie est du type POST. Le contenu est renvoyÊ vers le processus fils, sans transformation :
311 if (fwrite (argsbuffer, 1, len_read, script_out) == 0)
312 break;
... ...
335 pfclose (r->connection->pool, script_out);Il est donc clair que c'est Ă celui-ci d'exploiter ce qu'envoie le client, par exemple le rĂŠsultat d'une forme de saisie.
337 /* Handle script return... */
338 if (script_in && !nph) {
... ...
373 send_http_header(r);
374 if(!r->header_only) send_fd (script_in, r);
375 kill_timeout (r);
376 pfclose (r->connection->pool, script_in);
377 }Ce test traite le cas d'une CGI normale, dont la sortie est lue par le serveur, puis renvoyĂŠe au client (ligne 374).
Examinons maintenant comment se prÊpare et s'exÊcute le processus fils :
101 void CGI_child (void *child_stuff)
102 {
... ...
126 add_CGI_vars (r);
127 env = create_environment (r->pool, r->subprocess_env);Ces deux dernières lignes prÊparent l'environnement du futur processus fils. Il s'agit du tableau de variables accessibles depuis la variable externe environ, pour tout processus. La fonction add CGI vars (fichier util script.c, ligne 192) ajoute, entre autres, les variables REQUEST METHOD et QUERY STRING à l'environnement.
Cette dernière variable joue un rôle majeur dans la transmission des arguments à la CGI quand la mÊthode choisie est GET. En effet, dans ce cas, le seul moyen pour le client d'envoyer des arguments à la CGI est d'utiliser l'URL, comme dans :
- http://monweb.chez.moi/CGI-bin/nph-qtp?base=datas\&mot=acacia\&champ=.MC
La syntaxe de l'URL prÊvoit le caractère  ?  comme sÊparateur entre le nom et ses arguments. Chaque argument est ensuite Êcrit sous la forme :
- nom = valeur
Les arguments sont sÊparÊs les uns des autres par le caractère  & .
135 error_log2stderr (r->server);
136
... ...
138 if (nph) client_to_stdout (r->connection);Ligne 135, la sortie d'erreur est redirigÊe vers le fichier error log, et ligne 138, la sortie standard du processus, c'est la socket, donc envoyÊe directement vers le client !
184 if((!r->args) || (!r->args[0]) || (ind(r->args,'=') >= 0))
185 execle(r->filename, argv0, NULL, env);
186 else
187 execve(r->filename, create_argv(r->pool, argv0, r->args), env);Puis finalement on exĂŠcute la CGIÂ ! Bien sĂťr, si le programme va au-delĂ de la ligne 187, il s'agit d'une erreur...
16-4. Principe de fonctionnement des CGI▲
16-4-1. CGI - MĂŠthode GET, sans argument▲
Dans ce paragraphe nous examinons ce qui se passe lors de l'exÊcution d'une CGI très simple (shell script, le source suit) que l'on suppose placÊe dans le rÊpertoire idoine, pour être exÊcutÊe comme lors de la requête suivante :
$ telnet localhost 80
Trying ...
Connected to localhost.
Escape character is '^]'.
GET /CGI-bin/nph-test-CGI HTTP/1.0
HTTP/1.0 200 OK
Content-type: text/plain
Server: Apache/1.1.1L'entĂŞte du message HTTP renvoyĂŠ par le serveur. La ligne de statut est gĂŠnĂŠrĂŠe par la CGI car il s'agit d'une CGI de type nph-
CGI/1.0 test script report:
argc is 0. argv is .
SERVER_SOFTWARE = Apache/1.1.1
SERVER_NAME = www.chezmoi.tld
GATEWAY_INTERFACE = CGI/1.1
SERVER_PROTOCOL = HTTP/1.0
SERVER_PORT = 80
REQUEST_METHOD = GET
SCRIPT_NAME = /CGI-bin/nph-test-CGI
QUERY_STRING =
REMOTE_HOST = labas.tresloin.tld
REMOTE_ADDR = 192.168.0.1
REMOTE_USER =
CONTENT_TYPE =
CONTENT_LENGTH =
Connection closed by foreign host.Le corps du message. Ces octets sont gĂŠnĂŠrĂŠs dynamiquement par le programme nph-test-CGI.
Et voici le source de cet exemple (une modification du script de test livrĂŠ avec Apache)Â :
#!/bin/sh
echo HTTP/1.0 200 OK
echo Content-type: text/plain
echo Server: $SERVER_SOFTWARE
echo
echo CGI/1.0 test script report:
echo
echo argc is $#. argv is "$*".
echoRemarquez la fabrication de l'entête MIME, rÊduite, mais suffisante. Le echo seul gÊnère une ligne vide, celle qui marque la limite avec le corps du message.
echo SERVER_SOFTWARE = $SERVER_SOFTWARE
echo SERVER_NAME = $SERVER_NAME
echo GATEWAY_INTERFACE = $GATEWAY_INTERFACE
echo SERVER_PROTOCOL = $SERVER_PROTOCOL
echo SERVER_PORT = $SERVER_PORT
echo REQUEST_METHOD = $REQUEST_METHOD
echo QUERY_STRING = $QUERY_STRING
echo REMOTE_HOST = $REMOTE_HOST
echo REMOTE_ADDR = $REMOTE_ADDR
echo REMOTE_USER = $REMOTE_USER
echo CONTENT_TYPE = $CONTENT_TYPE
echo CONTENT_LENGTH = $CONTENT_LENGTHToutes ces variables sont celles de l'environnement gĂŠnĂŠrĂŠ par le module CGI handler avant d'effectuer le exec.
16-4-2. CGI - MĂŠthode GET, avec arguments▲
Examinons maintenant un cas plus compliquÊ, avec des arguments transmis, ou  query string . Celle-ci est transmise à la CGI via la variable d'environnement QUERY STRING. C'est à la CGI de l'analyser puisque son contenu relève de l'applicatif et non du serveur lui-même. Essayons de coder la CGI de l'exemple :
- http://www.chezmoi.tld/CGI-bin/query?base=datas\&mot=acacia\&champ=.MC
Première version :
#!/bin/sh
echo Content-type: text/plain
echo
echo "QUERY_STRING=>"$QUERY_STRING "<="
exit 0L'interrogation avec un Telnet produit la sortie :
QUERY_STRING=>base=datas&mot=acacia&champ=.MC<=Se trouve très facilement sur les sites FTP le source d'un outil nommÊ CGIparse(208), parfaitement adaptÊ à l'analyse de la chaÎne transmise. D'oÚ la deuxième version :
#!/bin/sh
CGIBIN=~web/CGI-bin
BASE=?$CGIBIN/CGIparse -value base?
MOT=?$CGIBIN/CGIparse -value mot?
CHAMP=?$CGIBIN/CGIparse -value champ?Cette partie du code montre l'analyse du contenu de la variable QUERY STRING avec l'outil CGIparse.
echo Content-type: text/plain
echo
echo "BASE="$BASE
echo "MOT="$MOT
echo "CHAMP="$CHAMP
exit 0Et lĂ , la fabrication du message renvoyĂŠ. La CGI renvoie ses octets via un tube au serveur, c'est donc celui-ci qui se charge de fabriquer un entĂŞte MIME.
Puis le rÊsultat de l'exÊcution :
BASE=datas
MOT=acacia
CHAMP=.MC16-4-3. CGI - MĂŠthode POST▲
La mĂŠthode POST autorise un client Ă envoyer au serveur une liste de couples variable=valeur. Chaque couple est sĂŠparĂŠ des autres par une fin de ligne, c'est-Ă -dire (CR,LF).
Cette mĂŠthode est bien adaptĂŠe Ă la transmission d'informations collectĂŠes cĂ´tĂŠ client dans une forme(209) de saisie, et dont le volume est variable.
La liste des couples est Êcrite dans le corps du message, par le programme client, et ne fait pas partie de l'URL, comme c'est le cas pour la mÊthode GET. Il y a Êvidemment une limite au nombre maximum d'octets envoyÊ par le client, c'est le serveur qui en fixe la valeur(210). Du côtÊ du client, il faut prÊvenir le serveur, dans l'entête du message HTTP, de la taille du corps du message. Cela s'effectue avec le champ Content-length :.
L'exemple suivant ne fait que renvoyer la liste des couples lus, vers le client. Attention il ne fonctionne qu'avec Telnet.
$ telnet www.chezmoi.tld 80
Trying 192.168.0.2...
Connected to www.chezmoi.tld.
Escape character is '^]'.
POST /CGI-bin/test-post HTTP/1.0
Content-length:14
areuh=tagadaLe corps du message fait bien 14 caractères si on compte la fin de ligne (CR+LF).
HTTP/1.0 200 OK
Date: Mon, 24 Mar 1997 14:41:26 GMT
Server: Apache/1.1.1
Content-type: text/plain
REQUEST_METHOD = POST
CONTENT_LENGTH = 14
Couple lu : areuh=tagada
Connection closed by foreign host.La rÊponse du serveur liste les couples lus, ici un seul ! La variable globale REQUEST METHOD pourrait être utilisÊe pour adapter le comportement de la CGI en fonction de la mÊthode demandÊe.
Et voici le source de la CGIÂ :
#!/bin/sh
#
# Ce script teste la mĂŠthode POST
#
echo Content-type: text/plain
echo
echo REQUEST_METHOD = $REQUEST_METHOD
echo CONTENT_LENGTH = $CONTENT_LENGTH
while read l
do
echo "Couple lu :" $l
done
exit 016-4-4. Ăcriture d'une CGI en Perl▲
Voir cours de Jean-Jacques Dhenin.
16-5. Conclusion - Bibliographie▲
Rien n'est constant, tout change... Et il faut être constamment à l'affÝt de la nouveautÊ dans ce domaine très rÊactif qu'est-celui du  World Wide Web .
Les quelques rÊfÊrences bibliographiques qui suivent illustrent ce cours, mais il est Êvident qu'elles sont bien insuffisantes pour couvrir tous les aspects que le terme  web  sous-entend !
- RFC 1521 N. Borenstein, N. Freed,  MIME (Multipurpose Internet Mail Extensions) Part One : Mechanisms for Specifying and Describing the Format of Internet Message Bodies, 09/23/1993. (Pages=81) (Format=. txt, .ps) (Obsoletes RFC1341) (Updated by RFC1590)
- RFC 1590 J. Postel,  Media Type Registration Procedure , 03/02/1994. (Pages=7) (Format=.txt) (Updates RFC1521)
- RFC 1630 T. Berners-Lee,  Universal Resource Identifiers in WWW : A Unifying Syntax for the Expression of Names and Addresses of Objects on the Network as used in the World-Wide Web , 06/09/1994. (Pages=28) (Format=.txt)
- RFC 1738 T. Berners-Lee, L. Masinter, M. McCahill, ÂŤÂ Uniform Resource Locators (URL)Â Âť, 12/20/1994. (Pages=25) (Format=.txt)
- RFC 1945 T. Berners-Lee, R. Fielding, H. Nielsen, ÂŤÂ Hypertext Transfer Protocol - HTTP/1.0Â Âť, 05/17/1996. (Pages=60) (Format=.txt)
- RFC 2068 R. Fielding, J. Gettys, J. Mogul, H. Frystyk, T. Berners- Lee, ÂŤÂ Hypertext Transfer Protocol - HTTP/1.1Â Âť, 01/03/1997. (Pages=162) (Format=.txt)
- TCP/IP Illustrated Volume 3 W. Richard Stevens - Addison-Wesley - janvier 1996.