


10. Serveur de noms - DNS▲
10-1. GĂ©nĂ©ralitĂ©s sur le serveur de noms▲
S'il est obligatoire d'attribuer au moins une adresse IP à une pile ARPA pour pouvoir l'interconnecter en réseau avec d'autres piles de même nature, en revanche, lui attribuer un nom symbolique n'est absolument pas nécessaire au bon fonctionnement de ses trois couches basses.
Ce nommage symbolique est simplement beaucoup plus naturel pour nos cerveaux humains que la manipulation des adresses IP, même sous forme décimale pointée (adresses IP). Il n'intervient donc qu'au niveau applicatif, ainsi la majeure partie des applications réseau font usage de noms symboliques avec, de manière sous-jacente, une référence implicite à leur(s) correspondant(s) numérique(s).
Ce chapitre explore les grandes lignes du fonctionnement de ce que l'on nomme le « serveur de noms », lien entre cette symbolique et l'adressage IP qui lui est associé.
Pour terminer cette introduction, il n'est pas innocent de préciser que le serveur de noms est en général le premier service mis en route sur un réseau, tout simplement parce que beaucoup de services le requièrent pour accepter de fonctionner (le courrier électronique en est un exemple majeur). C'est la raison pour laquelle l'usage d'adresses IP sous la forme décimale pointée reste de mise lors de la configuration des éléments de commutation et de routage(100).
10-1-1. Bref historique▲
Au début de l'histoire de l'Internet, la correspondance entre le nom (les noms s'il y a des synonymes ou « alias ») et l'adresse (il peut y en avoir plusieurs associées à un seul nom) d'une machine est placée dans le fichier /etc/hosts, présent sur toutes les machines Unix dotées d'une pile Arpa.
Ci-après le fichier en question, prélevé (et tronqué partiellement) sur une machine FreeBSD(101) à jour. On y remarque qu'il ne contient plus que l'adresse de « loopback » en ipv6 et ipv4.
# $FreeBSD$
#
# Host Database
#
# This file should contain the addresses and aliases for local hosts that
# share this file. Replace 'my.domain' below with the domainname of your
# machine.
#
# In the presence of the domain name service or NIS, this file may
# not be consulted at all; see /etc/nsswitch.conf for the resolution order.
##
::1 localhost localhost.my.domain
127.0.0.1 localhost localhost.my.domainAu début des années 1980 c'est le NIC(102) qui gère la mise à jour continuelle de cette table (HOSTS.TXT), avec les inconvénients suivants :
- absence de structure claire dans le nommage d'où de nombreux conflits entre les noms des stations. Par exemple entre les dieux de la mythologie grecque, les planètes du système solaire, les héros historiques ou de bandes dessinées...
- centralisation des mises à jour, ce qui entraîne :
- une lourdeur du processus de mise à jour : il faut passer par un intermédiaire pour attribuer un nom à ses machines,
- un trafic réseau (ftp) en forte croissance (N2 si N est le nombre de machines dans cette table) et qui devient rapidement ingérable au vu des bandes passantes de l'époque (quelques kilobits par seconde), et surtout jamais à jour compte tenu des changements continuels.
D'après Douglas E. Comer, au milieu des années 1980 (1986) la liste officielle des hôtes de l'Internet contient 3100 noms et 6500 alias !
La forte croissance du nombre des machines a rendu obsolète cette approche.
10-1-2. Système hiĂ©rarchisĂ© de nommage▲
L'espace de noms, préalablement non structuré, est désormais réorganisé de manière hiérarchique, sous forme d'un arbre (et non d'un graphe).
Cette organisation entraîne une hiérarchisation des noms de machines et des autorités qui ont le pouvoir de les nommer, de les maintenir.
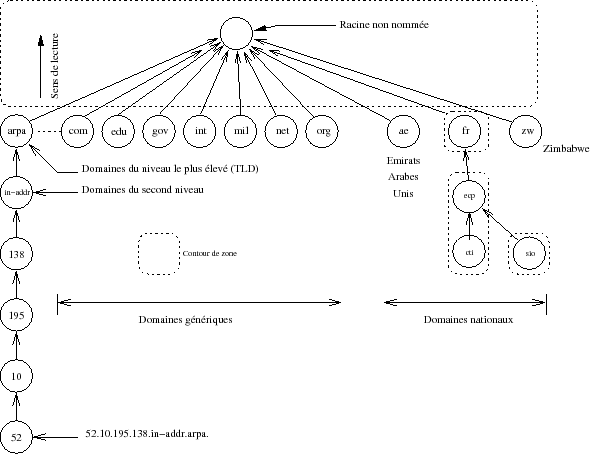
Chaque nœud de l'arbre porte un nom, la racine n'en a pas. Les machines, feuilles de l'arbre, sont nommées à l'aide du chemin parcouru de la feuille (machine) à la racine (non nommée).
Le séparateur entre chaque embranchement, ou nœud, est le point décimal. Voici un exemple de nom de machine :
- www.sio.ecp.fr
Derrière ce nom il faut imaginer un point (.) qui est omis la plupart du temps, car il est implicite(103). La lecture s'effectue naturellement de gauche à droite, par contre la hiérarchie de noms s'observe de droite à gauche.
10-1-2-1. Domaine & zone▲
Le réseau peut être considéré comme une hiérarchie de domaines. L'espace des noms y est organisé en tenant compte des limites administratives ou organisationnelles. Chaque nœud, appelé un domaine, est baptisé par une chaîne de caractères et le nom de ce domaine est la concaténation de toutes les étiquettes de nœuds lues depuis la racine, donc de droite à gauche. Par exemple :
| fr | Domaine fr |
| ecp.fr | Domaine ecp.fr, sous-domaine du fr |
| sio.ecp.fr | Domaine sio.ecp.fr, sous-domaine de ecp.fr |
Par construction, tout nœud est un domaine, même s'il est terminal, c'est-à -dire n'a pas de sous-domaine. Un sous-domaine est un domaine à part entière et, excepté la racine, tout domaine est un sous-domaine d'un autre.
Bien que le serveur de noms, « Domain Name Server » fasse référence explicitement au concept de domaine, pour bien comprendre la configuration d'un tel service il faut également comprendre la notion de « zone ».
Une zone est un point de délégation dans l'arbre DNS, autrement dit une zone concerne un sous-arbre du DNS dont l'administration lui est propre. Ce sous-arbre peut comprendre plusieurs niveaux, c'est-à -dire plusieurs sous-domaines. Une zone peut être confondue avec le domaine dans les cas les plus simples.
Dans les exemples ci-dessus, on peut parler de zone sio.ecp.fr puisque celle-ci est gérée de manière autonome par rapport à la zone ecp.fr.
Le serveur de noms est concerné par les « zones ». Ses fichiers de configuration(104) précisent la portée de la zone et non du domaine.
Chaque zone doit avoir un serveur principal (« master ») qui détient ses informations d'un fichier configuré manuellement ou semi-manuellement (DNS dynamique). Plusieurs serveurs secondaires (« slave ») reçoivent une copie de la zone via le réseau et pour assurer la continuité du service (par la redondance des serveurs).
Le fait d'administrer une zone est le résultat d'une délégation de pouvoir de l'administrateur de la zone parente et se concrétise par la responsabilité de configurer et d'entretenir le champ SOA (« start of authority ») de ladite zone.
10-1-2-2. HiĂ©rarchie des domaines▲
Cette organisation du nommage pallie aux inconvénients de la première méthode :
- le NIC gère le plus haut niveau de la hiérarchie, appelé aussi celui des « top levels domains » (TLD) ;
- les instances régionales du NIC gèrent les domaines qui leur sont dévolus. Par exemple le « NIC France »(105) gère le contenu de la zone .fr. Le nommage sur deux lettres des pays est issu de la norme ISO 3166(106) ;
- chaque administrateur de domaine (universités, entreprises, associations, entités administratives...) est en charge de son domaine et des sous-domaines qu'il crée. Sa responsabilité est nominative vis-à -vis du NIC. On dit aussi qu'il a l'autorité sur son domaine (« authoritative for the domain »)(107) ;
- les éventuels conflits de nommage sont à la charge des administrateurs de domaine. Du fait de la hiérarchisation, des machines de même nom peuvent se trouver dans des domaines différents sans que cela pose le moindre problème. Le nom « www » est de loin le plus employé(108), pourtant il n'y a aucune confusion possible entre ces machines, par exemple entre les machines www.ecp.fr et www.sio.ecp.fr.
- Chaque domaine entretient une base de données sur le nommage de ses machines. Celle-ci est mise à disposition de tous les utilisateurs du réseau. Chaque site raccordé de manière permanente procède de cette manière, ainsi il n'y a pas une base de données pour l'Internet, mais un ensemble structuré de bases de données reliées entre elles et formant une gigantesque base de données distribuée.
10-2. Fonctionnement du DNS▲
10-2-1. Convention de nommage▲
La RFC 1034 précise que les noms de machines sont développés un peu comme les noms d'un système de fichiers hiérarchisés (Unix...) et utilisent les caractères ASCII 7 bits assortis des contraintes suivantes :
- le « . » est le séparateur ;
- chaque nœud ne peut faire que 63 caractères au maximum; « le bon usage » les limite à douze caractères et commençant par une lettre ;
- les majuscules et minuscules sont indifférenciées ;
- les chiffres [0-9] et le tiret peuvent être utilisés, le souligné (_) est un abus d'usage ;
- le point « . » et le blanc « » sont proscrits ;
- les chaînes de caractères comme « NIC » ou d'autres acronymes bien connus sont à éviter absolument, même encadrées par d'autres caractères ;
- les noms complets ne doivent pas faire plus de 255 caractères de long.
Il y a des noms « relatifs » et des noms « absolus », comme des chemins dans un système de fichiers. L'usage du « . » en fin de nom, qui indique un nommage absolu(109), est réservé à certains outils comme ping ou traceroute et aux fichiers de configuration du serveur de noms. En règle générale il n'est pas utile de l'employer.
10-2-1-1. « Completion »▲
Sur un même réseau logique on a coutume de ne pas utiliser le nom complet des machines auxquelles on s'adresse couramment et pourtant ça fonctionne !
La raison est que le « resolver », partie du système qui est en charge de résoudre les problèmes de conversion entre un nom de machine et son adresse IP, utilise un mécanisme de complétion (« domain completion ») pour compléter le nom de machine simplifié, jusqu'à trouver un nom plus complet que le serveur de noms saura reconnaître dans sa base de données.
Le « resolver » connaît par hypothèse le ou les noms de domaine (lus dans le fichier de configuration /etc/resolv.conf) qui concernent la machine locale. Une station de travail n'en a généralement qu'un seul alors qu'un serveur peut en comporter plusieurs, par exemple si on souhaite consolider tout une palette de services pour plusieurs domaines sur une même machine.
Exemple d'un tel fichier :
domain sio.ecp.fr
search sio.ecp.fr., ecp.fr.
nameserver 138.195.52.68
nameserver 138.195.52.69
nameserver 138.195.52.132Plus généralement ce nom de domaine se présente sous la forme d1.d2...dn.
Ainsi, en présence d'un nom symbolique x, le « resolver » teste pour chaque i,
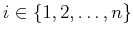
l'existence de x.di.di+1...dn et s'arrĂŞte si celle-ci est reconnue.
Dans le cas contraire, la machine en question n'est pas atteignable.
Exemple, avec le domaine ci-dessus :
- machine = www (requĂŞte)
- www.sio.ecp.fr ==>Succès !
- machine = www.sio (requĂŞte)
- www.sio.sio.ecp.fr ==>échec !
- www.sio.ecp.fr ==>Succès !
10-2-2. Le « Resolver »▲
Le « resolver » désigne un ensemble de fonctions(110) placées dans la bibliothèque standard (gethostbyname vu en cours de programmation invoque les fonctions du « resolver ») qui font l'interface entre les applications et les serveurs de noms. Par construction les fonctions du « resolver » sont compilées avec l'application qui les utilise (physiquement dans la libc, donc accessibles par défaut).
Le « resolver » applique la stratégie locale de recherche, définie par l'administrateur de la machine, pour résoudre les requêtes de résolution de noms.
Pour cela il s'appuie sur son fichier de configuration /etc/resolv.conf et sur la stratégie locale (voir paragraphe suivant) d'emploi des possibilités (serveur de noms, fichier /etc/nsswitch.conf, NIS...).
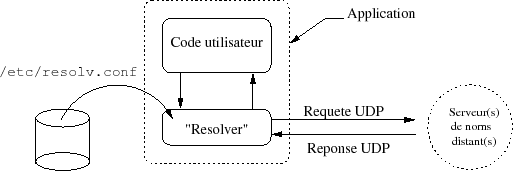
Le fichier /etc/resolv.conf précise au moins le domaine local assorti de directives optionnelles.
10-2-3. StratĂ©gie de fonctionnement▲
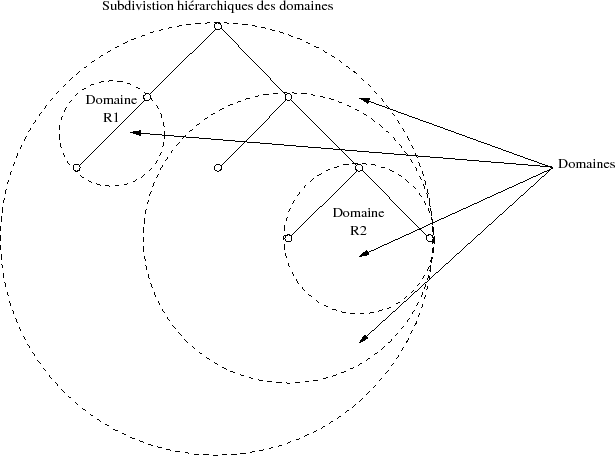
La figure IX.03 illustre le fait que chaque serveur de noms a la maîtrise de ses données, mais doit interroger ses voisins dès qu'une requête concerne une zone sur laquelle il n'a pas l'autorité de nommage.
Ainsi, un hôte du domaine « R2 » qui veut résoudre une adresse du domaine « R1 » doit nécessairement passer par un serveur intermédiaire pour obtenir l'information. Cette démarche s'appuie sur plusieurs stratégies possibles, que nous examinons dans les paragraphes suivants.
10-2-3-1. Interrogation locale▲
La figure ci-dessous illustre la recherche d'un nom dans le domaine local.
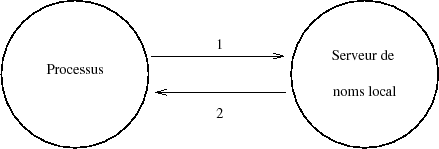
Un processus (« browser » HTTP par exemple) recherche l'adresse d'un nom de serveur. Sur les machines Unix cela se traduit par l'appel à la fonction gethostbyname. Cette fonction est systématiquement présente dans la bibliothèque standard (libc) et est donc accessible potentiellement à tout exécutable lors d'une compilation.
La fonction gethostbyname fait systématiquement appel au « resolver » déjà cité. C'est donc toujours en passant par ce mécanisme que les processus accèdent à l'espace de noms. Le « resolver » utilise une stratégie générale à la machine (donc qui a été choisie par son administrateur) pour résoudre de telles requêtes :
- Interrogation du serveur de noms (DNS) si présent.
- Utilisation des services type « YP » (NIS) si configurés.
- Utilisation du fichier /etc/hosts.
Cette stratégie est paramétrable en fonction du constructeur. Le nsswitch sous HP-UX(111) ou Solaris(112) permet de passer de l'un à l'autre en cas d'indisponibilité, le fichier /etc/nsswitch.conf sous FreeBSD effectue un travail assez proche.
Enfin, quelle que soit l'architecture logicielle le « resolver » est configuré à l'aide du fichier /etc/resolv.conf.
Sur la figure IX.04Â :
- Le processus demande l'adresse IP d'un serveur. Le « resolver » envoie la demande au serveur local.
- Le serveur local reçoit la demande, parce qu'il a l'autorité sur le domaine demandé (le sien), il répond directement au « resolver ».
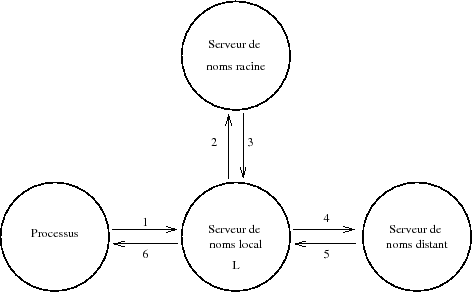
10-2-3-2. Interrogation distante▲
- Un processus demande l'adresse IP d'une machine. Le « resolver » envoie sa requête au serveur local.
- Le serveur local reçoit la requête et dans ce deuxième cas il ne peut pas répondre directement, car la machine n'est pas dans sa zone d'autorité. Pour lever l'indétermination, il interroge alors un serveur racine pour avoir l'adresse d'un serveur qui a l'autorité sur la zone demandée par le processus.
- Le serveur racine renvoie l'adresse d'un serveur qui a officiellement l'autorité sur la zone.
- Le serveur local interroge ce nouveau serveur distant.
- Le serveur distant renvoie l'information demandée au serveur local.
- Le serveur local retourne la réponse au « resolver ».
Remarques importantes :
- un mécanisme de cache accélère le processus ci-dessus : si un processus redemande la même machine distante, on se retrouve dans le cas d'une interrogation « locale », du moins pendant la durée de validité des données ;
- si un processus demande une machine du même domaine que la précédente (mais pas du même nom !), les étapes 2 et 3 deviennent inutiles et le serveur local interroge alors directement le serveur distant. La durée de vie de l'adresse du serveur distant est, elle aussi, assortie d'une date limite d'utilisation ;
- dans le cas général, les serveurs racines ne voient pas plus d'un ou deux niveaux en dessous. Ainsi, si un processus demande A.B.C.D.net :
- le serveur racine donne l'adresse d'un serveur pour D,
- le serveur pour D donnera peut-être l'adresse d'un serveur pour C et ainsi jouera le rôle de serveur racine de l'étape précédente,
- le serveur racine donne l'adresse d'un serveur pour D,
- le serveur pour D donnera peut être l'adresse d'un serveur pour C et ainsi jouera le rôle de serveur racine de l'étape précédente ;
- on dit également que le serveur L de la figure IX.05 fonctionne en mode récursif.
10-2-3-3. Interrogation par « procuration »▲
Le processus de recherche décrit au paragraphe précédent ne convient pas dans tous les cas, notamment vis-à -vis des deux critères suivants :
- Sécurité d'un domaine.
- Conservation de la bande passante.
- La figure IX.05 montre le serveur local qui interroge directement les serveurs distants, cette démarche pose des problèmes de sécurité dans le cas d'un domaine au sein duquel seuls un ou deux serveurs sont autorisés. Par exemple le serveur de noms du domaine sio.ecp.fr n'interroge pas directement le serveur racine, il passe par le serveur officiel qui est piston.ecp.fr (138.195.33.3).
- Le trafic destiné au serveur de noms peut consommer une partie non négligeable de la bande passante, c'est pourquoi il peut être stratégique de concentrer les demandes vers un seul serveur régional et donc de bénéficier au maximum de l'effet de cache décrit précédemment.
10-2-4. HiĂ©rarchie de serveurs▲
Si tous les serveurs de noms traitent des données d'un format identique, leur position dans l'arborescence leur confère un statut qui se nomme :
- serveur racine (« root name server »), un serveur ayant autorité sur la racine de l'espace de nommage. Actuellement il y a 13 serveurs de ce type, nommés [A-M].ROOT-SERVERS.NET(113) ;
- serveur primaire (« master »), un serveur de noms qui a l'autorité pour un ou plusieurs domaines (est détenteur d'autant de SOA). Il lit ses données dans un fichier stocké sur disque dur à son démarrage. L'administrateur du (des) domaine(s) met à jour les informations des domaines concernés depuis cette machine ;
- serveur secondaire (« slave »), dans le cas d'une panne ou d'un engorgement du serveur primaire, les serveurs secondaires reçoivent en prévision une copie de la base de données.
- Stratégiquement il est préférable de les placer en dehors du domaine, sur le réseau d'un autre FAI. Il peut y avoir autant de serveurs secondaires que souhaité, de l'ordre de trois ou quatre est souvent rencontré.
- Au démarrage ils reçoivent les informations du serveur primaire, ou ils les lisent sur leur disque dur s'ils ont eu le temps de les y stocker au précédent arrêt du serveur, et si elles sont encore valides.
Par exemple, le serveur PISTON.ECP.FR a comme serveurs secondaires NS2.NIC.FR, SOLEIL.UVSQ.FR, MANOUL.CTI.ECP.FR.
10-2-5. Conversion d'adresses IP en noms▲
On dit aussi questions inverses (« inverse queries » vs « reverse queries »).
Cette possibilité est indiquée comme optionnelle dans la RFC 1034, mais est néanmoins bien commode voire fréquemment requise pour le client réseau de services comme le courrier électronique, l'établissement de sessions à distance avec ssh ou même les serveurs de fichiers anonymes (ftp). Si une machine est enregistrée dans le TLD in-addr.arpa, c'est un indicateur favorable quant à la qualité d'administration du réseau qui l'héberge, mais ne prouve rien quant aux bonnes intentions de son (ses) utilisateur(s).
Il faut ajouter que le bon usage sur les réseaux est de prévoir une entrée dans la zone reverse pour toutes les machines utiles et utilisées d'un réseau accessible de l'Internet. Le contraire provoque bien souvent la grogne (à juste titre) des administrateurs.
Il faut reconsidérer la figure IX.01., à gauche de la figure on distingue un domaine un peu particulier « in-addr.arpa ». Toutes les adresses sont exprimées dans le « top level domain » :
- in-addr.arpa
Du fait de la lecture inverse de l'arbre, les adresses IP sont exprimées en « miroir » de la réalité. Par exemple pour la classe B de l'ecp :
- 195.138.in-addr.arpa (Classe B 138.195)
Le fonctionnement par délégation est calqué sur celui utilisé pour les noms symboliques (c'est la justification de son insertion dans la figure IV.01). Ainsi, on peut obtenir la liste des serveurs ayant autorité sur la zone 195.138.in-addr.arpa en questionnant d'abord les serveurs du TLD in-addr.arpa puis ceux pour la zone 138.in-addr.arpa, et ainsi de suite...
Chaque administrateur de zone peut aussi être en charge de l'administration des « zones reverses », portion du domaine « arpa », des classes d'adresses dont il dispose pour nommer ses machines, s'il en reçoit la délégation. Il faut bien noter que cette délégation est une opération indépendante de celle qui a lieu pour les autres domaines.
Notons également que la notion de sous-réseau n'est pas applicable au domaine « in-addr.arpa », ce qui signifie que les adresses sont regroupées selon les contours naturels des octets.
Ainsi, pour les clients de fournisseurs d'accès n'ayant comme adresses IP officielles que celles délimitées par un masque de sous-réseau large seulement que de quelques unités (< 254), la gestion de la « zone reverse » reste du domaine du prestataire (FAI) et non du client.
10-2-6. Conclusion▲
Qu'est-ce qu'un DNSÂ ?
Un serveur de noms repose sur trois constituants :
- Un espace de noms et une base de données qui associe de manière structurée des noms à des adresses IP.
- Des serveurs de noms, qui sont compétents pour répondre sur une ou plusieurs zones.
- Des « resolver » capables d'interroger les serveurs avec une stratégie définie par l'administrateur du système.
TCP ou UDPÂ ?
Le port 53 « bien connu » pour le serveur de noms est prévu pour fonctionner avec les deux protocoles.
Normalement la majeure partie du trafic se fait avec UDP, mais si la taille d'une réponse dépasse les 512 octets, un drapeau de l'entête du protocole l'indique au client qui reformule sans question en utilisant TCP.
Quand un serveur secondaire démarre son activité, il effectue une connexion TCP vers le serveur primaire pour obtenir sa copie de la base de données. En général, toutes les trois heures (c'est une valeur courante) il effectue cette démarche.
10-3. Mise Ă jour dynamique▲
La mise à jour dynamique de serveur de noms (RFC 2136) est une fonctionnalité assez récente sur le réseau, elle permet comme son nom l'indique de mettre à jour la base de données répartie.
Aussi bien au niveau du réseau local qu'à l'échelle de l'Internet il s'agit le plus souvent de faire correspondre un nom de machine fixe avec une adresse IP changeante. C'est typiquement le cas d'un tout petit site qui a enregistré son domaine chez un vendeur quelconque et qui au gré des changements d'adresse IP (attribuée dynamiquement par exemple avec DHCP(114)) par son fournisseur d'accès, met à jour le serveur de noms pour être toujours accessible.
Avec comme mot clef « dyndns », les moteurs de recherche indiquent l'existence de sites commerciaux ou à caractère associatif, qui proposent cette fonctionnalité.
10-4. SĂ©curisation des Ă©changes▲
Le serveur de noms est la clef de voûte des réseaux, et c'est en même temps un de ses talons d'Achille parce que les programmes que nous employons quotidiennement utilisent sans discernement l'information acquise du réseau. En effet, qu'est-ce qui vous assure que le site web de votre banque sur lequel vous venez de taper votre mot de passe est bien le vrai site officiel de cet établissement ? L'apparence de la page de garde ?
Typiquement il y a deux situations de vulnérabilité :
- Dialogue serveur Ă serveur, notamment lors de transferts de zones.
- Interrogation d'un serveur par un « resolver ».
Pour faire confiance en ce que vous dit le serveur de noms interrogé il faut d'une part que vous soyez certains d'interroger la bonne machine et d'autre part que celle-ci soit détentrice d'une information incontestable.
C'est une chaîne de confiance, comme toujours en sécurité, qui remonte par construction du fonctionnement du serveur de noms interrogé par votre application (comme nous l'avons examiné dans les paragraphes qui précèdent) jusqu'aux serveurs racines.
La version ISC (consultez le paragraphe 7) du programme BIND utilise deux stratégies différentes, selon les cas ci-dessus. Dans le premier cas, il s'agit d'un mécanisme nommé TSIG/TKEY, dans le deuxième DNSSEC.
TSIG/TKEY utilisent une clef symétrique, donc partagée par les deux serveurs (cette clef leur est connue par des mécanismes différents). DNSSEC utilise un mécanisme basé sur le principe d'un échange de clefs publiques.
Outre les dysfonctionnements dus à une information erronée, on observe également des attaques de type « déni de service(115) » utilisant le fonctionnement intrinsèque du protocole (voir plus loin).
10-4-1. TSIG/TKEY pour sĂ©curiser les transferts▲
L'usage d'une clef symétrique indique qu'il s'agit d'un secret partagé entre deux serveurs. La même clef sert au chiffrement et au déchiffrement des données.
Le bon usage veut que l'on dédie une clef à un certain type de transaction (par exemple le transfert d'une zone) entre deux serveurs donnés. Cette manière de procéder se traduit donc rapidement par un grand nombre de clefs à gérer ce qui interdit un déploiement généralisé sur l'Internet.
Pour éviter de trop longs temps de chiffrement, ce ne sont pas les données à transférer qui sont chiffrées (de plus elles ne sont pas confidentielles), mais leur empreinte (« fingerprints ») avec un algorithme de type MD5 ou SHA1(116).
Cette empreinte, seule, est cryptée.
Le serveur qui reçoit un tel paquet signé, calcule l'empreinte du paquet avec le même algorithme, déchiffre celle jointe avec la clef secrète partagée et compare les deux empreintes. Le résultat de cette comparaison dit si les données sont valides ou non.
L'intérêt de ces transferts signés est que les serveurs secondaires sont certains de mettre à jour leurs zones avec des données qui proviennent bien du détenteur du SOA et qui sont absolument semblables à ce qui a été émis.
10-4-1-1. TSIG▲
TSIG comme « Transaction SIGnature » est la méthode décrite dans la RFC 2845 et basée sur l'usage d'une clef symétrique. La génération de cette clef peut être manuelle ou automatisée avec le programme « dnssec-keygen ».
La propagation de cette clef est manuelle (scp...éviter absolument l'usage de tout protocole diffusant un mot de passe en clair sur le réseau), donc mise en place au coup par coup.
TSIG sert également à la mise à jour dynamique (« dynamic update »), la connaissance de la clef par le client sert à la fois à l'authentifier et à signer les données(117).
10-4-1-2. TKEY▲
TKEY, décrit dans la RFC 2930, rend les mêmes services que TSIG tout en évitant le transport du secret (TSIG). Cette caractéristique est basée sur le calcul de la clef symétrique automatiquement avec l'algorithme de Diffie-Hellman plutôt que par un échange « manuel »(118).
Par contre, cet algorithme à base du tandem clef publique - clef privée suppose l'ajout d'un champ KEY dans les fichiers de configuration du serveur. Comme d'ailleurs le mécanisme suivant...
10-4-2. DNSSEC pour sĂ©curiser les interrogations▲
DNSSEC décrit dans la RFC 2535 permet :
- La distribution d'une clef publique (champ KEY).
- La certification de l'origine des données.
- L'authentification des transactions (transferts, requĂŞtes).
Mis en place, le DNSSEC permet de construire une chaîne de confiance, depuis le « top level » jusqu'au serveur interrogé par votre station de travail.
10-5. Attaque DNS par amplification▲
Le fonctionnement repose sur UDP, protocole pour lequel l'entête est facilement falsifiable, notamment sur l'adresse de retour. Il est ainsi très facile d'envoyer une requête à un serveur, avec une adresse de retour qui est celle d'une machine victime plutôt que la sienne :
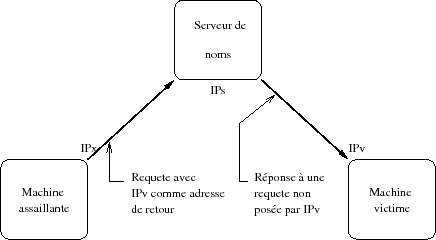
Sur la figure IX.06 la machine d'adresse IPv reçoit un message du serveur de noms d'adresse IP, non sollicité. Il est bien évident qu'un seul message de ce type reste sans effet, cependant :
- Le volume en octets de la réponse peut être considérablement plus important que celui de la requête, notamment si le serveur de noms est configuré par l'assaillant. Par exemple d'un facteur 5 ou 10.
- L'assaillant peut envoyer un très grand nombre de requêtes à des serveurs ouverts en mode récursif pour toute requête ne portant pas sur les domaines sur lesquels ils ont autorité.
La machine victime est alors submergée par un flot de réponses qui saturent complètement ses accès réseaux, c'est une une attaque DNS par amplification(119) et qui provoque un déni de service sur le site qui la subit.
Le schéma d'ensemble d'une telle attaque est résumé sur la figure IX.07.
La machine assaillante (elles peuvent être nombreuses, des centaines de milliers) bombarde les serveurs (S1, S2,...Sn) de fausses requêtes. Ces serveurs sont utilisés parce qu'ils combinent deux propriétés intéressantes :
- Ils sont ouverts aux requêtes extérieures même et surtout celles qui ne portent pas sur leurs données. Cette propriété est héritée de l'époque ou l'Internet était encore un réseau d'universitaires et d'informaticiens. Cette propriété devrait tendre à disparaître, mais c'est loin d'être encore le cas(120) puisque la configuration standard des outils l'autorise et que les compétences techniques ne sont pas assez nombreuses.
- Ils utilisent un cache DNS. L'effet de ce cache est que même si la machine « source » est isolée du réseau, les enregistrements lus, pourvu qu'ils soient assortis d'un temps de vie suffisant (TTL) peuvent continuer d'être exploités.
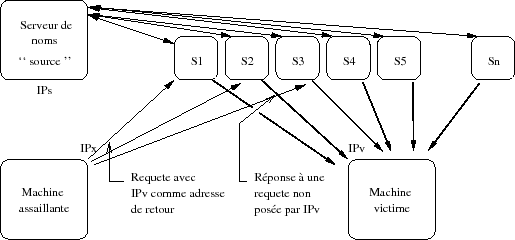
Quelques remarques :
- Le serveur de noms « source » n'est pas nécessairement complice, c'est tout simplement un serveur avec de gros enregistrements.
- Les serveurs S1 à Sn sont utilisés à leur insu, mais une configuration soigneuse peut éviter cet abus d'usage.
- Une fois attaqué le serveur victime ne peut pas faire grand-chose. Ses services ne sont plus accessibles, car le réseau est saturé.
- La parade avec un serveur de type Bind de l'ISC consiste à explicitement limiter l'ouverture extérieure du serveur aux seules données sur lesquelles il a autorité(121).
L'accès aux données dans le cache doit également être protégé, car d'autres techniques existent pour peupler les caches, par exemple envoyer un mail qui nécessite l'interrogation du serveur source.
10-6. Format des « Resource Record »▲
Comme pour toute base de données, le serveur de noms a un format pour ses champs, ou « Resource Record », RR dans la suite de ce texte, défini à l'origine dans la RFC 1035.
En pratique toutes les distributions (commerciales ou libres) du serveur de noms conservent ce format de base de données, la mise en œuvre du serveur seule change (fichier de configuration du daemon).
Un serveur de noms a autorité (responsabilité du SOA) sur une ou plusieurs zones, celles-ci sont repérées dans ses fichiers de configuration (named.conf ou named.boot selon les versions). S'il est serveur primaire d'une ou plusieurs zones, le contenu de ces zones est inscrit dans des fichiers ASCII ; leur syntaxe est succinctement décrite dans le paragraphe suivant.
S'il est serveur secondaire, le fichier de configuration indique au serveur de quelle(s) zone(s) il est secondaire (il peut ĂŞtre secondaire d'un grand nombre de zones) et donc oĂą (adresse IP) il devra aller chercher cette information.
Cette action se traduit par ce que l'on nomme un « transfert de zone ». Ce transfert est effectué automatiquement à la fréquence prévue par l'administrateur du champ SOA et donc connue dès le premier transfert. En cas de changement sur le serveur principal, celui-ci avertit (« Notify ») ses serveurs secondaires de la nécessité de recharger la zone pour être à jour.
Le propos de ce qui suit n'est pas de se substituer à une documentation nombreuse et bien faite sur le sujet, mais d'apporter quelques éléments fondamentaux pour en aider la lecture.
Le constituant de base d'un serveur de noms est une paire de fichiers ASCII contenant les enregistrements, les « Resource Record ».
Ceux-ci sont en général écrits sur une seule ligne de texte (sauf pour le champ SOA qui s'étale sur plusieurs lignes. Le marqueur de fin de ligne (CR+LF) est aussi celui de la fin de l'enregistrement. Le contenu général d'un tel enregistrement a la forme suivante (les accolades indiquent des données optionnelles) :
{name} {ttl} addr-class Record Type Record Specific dataCinq enregistrements, ou « Resource Record », ou en RR, sont absolument fondamentaux pour faire fonctionner un serveur de noms : SOA, NS, A, MX et PTR.
10-6-1. RR de type SOA▲
$(ORIGIN) sio.ecp.fr.
name {ttl} addr-class SOA Origin Person in charge
@ IN SOA sio.ecp.fr. hostmaster.sio.ecp.fr. (
2007100801 ; Serial
10800 ; Refresh (3h)
3600 ; Retry (1H)
3600000 ; Expire (5w6d16h)
86400 ) ; Minimum ttl (1D)SOA est l'acronyme de « Start Of Authority » et désigne le début obligé et unique d'une zone. Il doit figurer dans chaque fichier db.domain et db.adresse. Le nom de cette zone est ici repéré par le caractère @ qui signifie la zone courante, repérée par la ligne au-dessus « $(ORIGIN) sio.ecp.fr. ».
La ligne aurait également pu s'écrire :
sio.ecp.fr. IN SOA sio.ecp.fr. hostmaster.sio.ecp.fr. (...)Un problème concernant cette zone devra être signalé par e-mail à hostmaster@sio.ecp.fr (notez le « . » qui s'est transformé en « @ »).
Les paramètres de ce SOA sont décrits sur plusieurs lignes, regroupées entre parenthèses. Le caractère « ; » marque le début d'un commentaire, qui s'arrête à la fin de ligne.
Les points en fin de noms sont nécessaires.
Le numéro de série doit changer à chaque mise à jour de la zone (sur le serveur principal). Le Refresh indique la fréquence, en secondes, à laquelle les serveurs secondaires doivent consulter le primaire pour éventuellement lancer un transfert de zone (si le numéro de série est plus grand). Le Retry indique combien de secondes un serveur secondaire doit attendre un transfert avant de le déclarer impossible. Le Expire indique le nombre de secondes maximum pendant lesquelles un serveur secondaire peut se servir des données du primaire en cas d'échec du transfert. Minimum ttl est le nombre de secondes par défaut pour le champ TTL si celui-ci est omis dans les RR.
10-6-2. RR de type NS▲
Il faut ajouter une ligne de ce type (« Name Server ») pour chaque serveur de noms pour le domaine. Notez bien que rien dans la syntaxe ne permet de distinguer le serveur principal de ses secondaires.
Dans le fichier db.domaine :
{name} {ttl} addr-class NS Name servers name
IN NS ns-master.sio.ecp.fr.
IN NS ns-slave1.sio.ecp.fr.
IN NS ns-slave2.sio.ecp.fr.Dans le fichier qui renseigne la zone « reverse », par exemple db.adresse, on trouvera :
52.195.138.in-addr.arpa. IN NS ns-master.sio.ecp.fr.
52.195.138.in-addr.arpa. IN NS ns-slave1.sio.ecp.fr.
52.195.138.in-addr.arpa. IN NS ns-slave2.sio.ecp.fr.10-6-3. RR de type A▲
Le RR de type A, ou encore « Address record » attribue une ou plusieurs adresses à un nom, c'est donc celui qui est potentiellement le plus fréquemment utilisé. Il doit y avoir un RR de type A pour chaque adresse d'une machine.
{name} {ttl} addr-class A address
gw-sio IN A 138.195.52.2
IN A 138.195.52.33
IN A 138.195.52.6510-6-4. RR de type PTR▲
Le RR de type PTR, ou encore « PoinTeR record » permet de spécifier les adresses pour la résolution inverse, donc dans le domaine spécial IN-ADDR.ARPA. Notez le « . » en fin de nom qui interdit la complétion (il s'agit bien du nom FQDN).
name {ttl} addr-class PTR real name
2 IN PTR gw-sio.sio.ecp.fr.
33 IN PTR gw-sio.sio.ecp.fr.
65 IN PTR gw-sio.sio.ecp.fr.10-6-5. RR de type MX▲
Le RR de type MX, ou encore « Mail eXchanger » concerne les relations entre le serveur de noms et le courrier électronique. Nous examinerons son fonctionnement ultérieurement dans le chapitre sur le courrier électronique.
sio.ecp.fr. IN MX 10 smtp.ecp.fr.
sio.ecp.fr. IN MX 20 mailhost.laissus.fr.10-6-6. RR de type CNAME▲
Le RR de type CNAME, ou encore « canonical name » permet de distinguer le nom officiel d'une machine de ses surnoms.
www.sio.ecp.fr. IN CNAME msio-bipro.cti.ecp.fr.Dans l'exemple ci-dessus, la machine www.sio.ecp.fr est un surnom de la machine msio-bipro.cti.ecp.fr. Le fait que ces deux appellations soient dans la mĂŞme zone (ecp.fr.) n'aide en rien au bon fonctionnement du dispositif.
La machine msio-bipro pourrait être hébergée n'importe où ailleurs sur un autre réseau dans une autre zone... !
Cette possibilité est très employée pour constituer des machines virtuelles, comme nous le verrons au chapitre VIII.
10-6-7. Autres RR.▲
Il existe d'autres RR, entre autres HINFO , TXT, WKS et KEY, non traités dans cette présentation parce qu'ils n'apportent rien à la compréhension du fonctionnement du serveur de noms. Le lecteur est fortement incité à se reporter au « Name Server Operations Guide » pour plus d'informations.
10-7. BIND de l'ISC▲
L'Internet Software Consortium(122) est une organisation non commerciale qui développe et favorise l'emploi de l'outil « Open Source » comme BIND (acronyme de « Berkeley Internet Name Domain »).
Cette version libre du serveur de noms est la plus employée sur les machines Unix du réseau, ce qui justifie que l'on s'y intéresse. Elle fournit une version du daemon « named » et un « resolver » intégré dans la libc. On peut aisément installer ce logiciel sur à peu près toutes les implémentations d'Unix connues (cf. le fichier INSTALL du répertoire src).
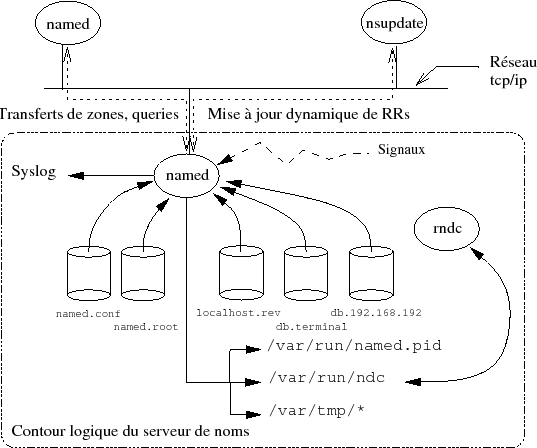
10-7-1. Architecture du daemon « named »▲
La figure IX.06 montre le schéma général de l'organisation logicielle du daemon « named ».
Au démarrage celui-ci lit sa configuration dans un fichier qui peut se nommer named.boot ou named.conf selon que l'on est en version 4.9.11, 8.3.6 ou 9.2.9 et les suivantes du logiciel(123).
- named.conf : c'est le fichier de configuration lu au démarrage. Sa structure dépend de la version du logiciel, heureusement dans les deux cas la sémantique reste proche !
- named.root : ce fichier contient la liste des serveurs de la racine, leur nom et adresse IP.
- localhost.rev : ce fichier contient la base de données du « localhost ». Personne ne possède en particulier le réseau 127, donc chacun doit le gérer pour lui-même. L'absence de ce fichier n'empêche pas le serveur de fonctionner, mais ne lui permet pas de résoudre 127.0.0.xx (où xx est le numéro de la machine courante, souvent 1).
- db.terminal : exemple de fichier de base de données pour le domaine factice terminal.fr qui est utile durant les travaux pratiques. Ce fichier permet la conversion des noms en adresses IP.
- db.192.168.192 : ce fichier contient la base de données de la zone « reverse » pour le domaine terminal.fr, c'est-à -dire le fichier qui permet au logiciel de convertir les adresses IP en noms.
- rndc ou « name server control utility » est comme son nom l'indique un outil d'administration du programme named lui-même. C'est une alternative à l'usage direct des signaux. Le canal de communication entre les deux programmes est une socket Unix AF UNIX vs AF LOCAL (cf. cours de programmation).
Un certain nombre de signaux modifient le comportement du serveur, ils seront examinés en travaux pratiques, tout comme les fichiers lus ou écrits dans les répertoires /var/run et /var/tmp/.
Enfin la flèche vers syslog signifie que named utilise ce service pour laisser une trace de son activité (cf. cours sur l'architecture des serveurs).
Enfin, le BOG, c'est-à -dire le « Bind Operations Guide », détaille le contenu des champs de la base de données des versions 4.x et 8.x. Pour la version 9.x est distribuée avec « BIND 9 Administrator Reference Manual » une documentation également très bien faite.
10-8. Bibliographie▲
Quand on « sait déjà  », la page de man de « named » suffit à vérifier un point obscur ! Sinon il existe une documentation très fournie sur le sujet, avec notamment :
- Kein J. Dunlap & Michael J. Karels - « Name Server Operations Guide » - Ce document est accessible sur le serveur de l'Internet Software Consortium (124).
- By the Nominum BIND Development Team - « BIND 9 Administrator Reference Manual » - Version 9.1.3 (125).
- Douglas E. Comer - « Internetworking with TCP/IP - Volume I » (chapter 18) - Prentice All - 1988.
- Paul Albitz & Cricket Liu - « DNS and BIND » - O'Reilly & Associates, Inc. - 1992.
- « Installing and Administering ARPA Services » - Hewlett Packard - 1991.
- W. Richard Stevens - « TCP/IP Illustrated Volume I » (chapter 14) - Prentice All - 1994.
Et pour en savoir encore plus...
- RFC 1034 « Domain names - concepts and facilities ». P.V. Mockapetris. Nov-01-1987. (Format : TXT=129180 bytes) (Obsoletes RFC0973, RFC0882, RFC0883) (Obsoleted by RFC1065, RFC2065) (Updated by RFC1101, RFC1183, RFC1348, RFC1876, RFC1982, RFC2065, RFC2181) (Status : STANDARD)
- RFC 1035 « Domain names - implementation and specification ». P.V. Mockapetris. Nov-01-1987. (Format : TXT=125626 bytes) (Obsoletes RFC0973, RFC0882, RFC0883) (Obsoleted by RFC2065) (Updated by RFC1101, RFC1183, RFC1348, RFC1876, RFC1982, RFC1995, RFC1996, RFC2065, RFC2181, RFC2136, RFC2137) (Status : STANDARD)
- RFC 1101 « DNS encoding of network names and other types ». P.V. Mockapetris. Apr-01-1989. (Format : TXT=28677 bytes) (Updates RFC1034, RFC1035) (Status : UNKNOWN)
- RFC 1123 « Requirements for Internet hosts - application and support ». R.T. Braden. Oct-01-1989. (Format : TXT=245503 bytes) (Updates RFC0822) (Updated by RFC2181) (Status : STANDARD)
- RFC 1713 « Tools for DNS debugging ». A. Romao. November 1994. (Format : TXT=33500 bytes) (Also FYI0027) (Status : INFORMATIONAL)
- RFC 2136 « Dynamic Updates in the Domain Name System (DNS UPDATE) ». P. Vixie, Ed., S. Thomson, Y. Rekhter, J. Bound. April 1997. (Format : TXT=56354 bytes) (Updates RFC1035) (Updated by RFC3007) (Status : PROPOSED STANDARD)
- RFC 2535 « Domain Name System Security Extensions ». D. Eastlake 3rd. March 1999. (Format : TXT=110958 bytes) (Obsoletes RFC2065) (Updates RFC2181, RFC1035, RFC1034) (Updated by RFC2931, RFC3007, RFC3008, RFC3090, RFC3226, RFC3445) (Status : PROPOSED STANDARD)
- RFC 2845 « Secret Key Transaction Authentication for DNS (TSIG) » P. Vixie, O. Gudmundsson, B. Wellington. May 2000. (Format : TXT=32272 bytes) (Updates RFC1035) (Status : PROPOSED STANDARD)
- RFC 2930 « Secret Key Establishment for DNS (TKEY RR) » D. Eastlake 3rd. September 2000. (Format : TXT=34894 bytes) (Status : PROPOSED STANDARD)